PDF
Después de mucho tiempo sin liberar una nueva release, ya está aquí la versión 0.3 de peepdf. No es que no se haya trabajado en el proyecto, sino que después de añadir la opción de actualizar la herramienta desde línea de comandos, la liberación de nuevas versiones ha quedado relegada a un segundo plano. Además, a partir de enero de 2014 Google eliminó la opción de añadir nuevas descargas de los proyectos alojados en Google Code, así que tenía que pensar en una alternativa. Desde ahora los nuevos archivos se alojarán en eternal-todo.com, en la sección de releases.
Las diferencias con la versión 0.2 son notables: se han añadido nuevos comandos y funcionalidades, se han actualizado librerías, se cambió el motor de ejecución de Javascript, se añadió detección para varias vulnerabilidades, y, por supuesto, se han corregidos muchos bugs. Esta es la lista de los cambios más importantes (changelog completo aquí):
Enviado por jesparza el Lun, 2014/06/16 - 19:53.
Normalmente recibo SPAM con ejecutables y zips maliciosos. También los conocidos “documentos PDF” con doble extensión (.pdf.exe), pero hace unos días recibí un correo electrónico que tenía un PDF adjunto, sin extensión .exe oculta y no se trataba del típico anuncio de Viagra. Era bastante sospechoso. En ese momento no tenía mucho tiempo para analizarlo, así que lo dejé un poco de lado. Al día siguiente recibí otro con diferente asunto. El del primer correo era “Invoice 454889 April”, enviado por Sue Mockridge (motherlandjjw949 at gmail.com) y adjuntando “April invoice 819953.pdf” (eae0827f3801faa2a58b57850f8da9f5). El segundo tenía como asunto “Image has been sent jesparza”, enviado por Evernote Service (message at evernote.com, pero en las cabeceras se veía protectoratesl9 at gmail.com) y adjuntando “Agreemnet-81220097.pdf” (2a03ac24042fc35caa92c847638ca7c2).
Enviado por jesparza el Dom, 2014/06/15 - 14:43.
- Eliminar tags HTML innecesarios
- Convertir posibles elementos HTML llamados desde el código Javascript en variables en Javascript
- Buscar posibles funciones eval y sustituirlas por print o hookear la propia función si es posible (PyV8)
- Ejecutar el código Javascript
- Poner bonito el código (beautify)
- Buscar shellcodes o URLs de exploits
- Repetir los pasos si es necesario
Enviado por jesparza el Dom, 2013/08/18 - 22:29.
BlackHat USA 2013 ya está aquí y mañana estaré explicando cómo analizar exploit kits y documentos PDF en mi workshop “PDF Attack: From the Exploit Kit to the Shellcode” de 14:15 a 16:30 en la sala Florentine. Será una sesión práctica, así que traed vuestros portátiles y esperad algunos ejercicios para jugar ;) Sólo necesitáis una distribución Linux con pylibemu y PyV8 instalado para apuntarte a la fiesta. También se pueden seguir los ejercicios e instalar todo en Windows si se prefiere...
Ahora Spidermonkey ya no es necesario porque hace unos días decidí cambiar el motor Javascript a PyV8, ya que realmente funciona mucho mejor. Podéis echar un vistazo a la diferencia del análisis automático del código Javascript usando Spidermonkey (izquierda) y PyV8 (derecha).
Enviado por jesparza el Mié, 2013/07/31 - 13:33.
Además de los diferentes bugs corregidos, éstas son las principales novedades:
- Soporte para AES en el proceso de descifrado: Hasta ahora peepdf soportaba RC4 como algoritmo de descifrado, pero AES estaba en el TODO debido a las diferentes muestras que usaban este algoritmo para ocultar contenido malicioso. Según me comentaron en Las Vegas parece que habrá próximas modificaciones en la especificación PDF en este aspecto, por lo que es posible que haya más cambios en un futuro cercano.
Enviado por jesparza el Dom, 2012/08/05 - 17:06.
We can identify two known vulnerabilities and it seems that object 30 contains Javascript code. If we take a look at the filters used in this stream we see that peepdf has been able to decode the /CCITTFaxDecode filter without problems:
Enviado por jesparza el Lun, 2012/04/23 - 00:55.
Last week I presented the last version of peepdf in the Black Hat Europe Arsenal. It was a really good experience that I hope I can continue doing in the future ;) Since the very first version, almost one year ago, I had not released any new version but I have been frequently updating the project SVN. Now you can download the new version with some interesting additions (and bugfixes), and take a look at the overview of the tool in the slides. I think it's important to mention that the version included in the Black Hat CD and the one in the Black Hat Arsenal webpage IS NOT the last version, this IS the last version. I've asked the Black Hat stuff to change the version on the site so I hope this can be fixed soon.
Enviado por jesparza el Sáb, 2012/03/24 - 14:35.
Maybe it was not evident enough or not well documented, but until the moment there was a way of extracting streams, Javascript code, shellcodes and any type of information shown in the console output. What it's true is that it was not very straightforward. To extract something it was needed to set the especial variable "output" to a file or variable in order to store the console output in that new destination. For this to be accomplished we used the set command and after this the reset command to restore the original value of "output".
PPDF> set output file myFile
PPDF> rawstream 2
78 da dd 53 cb 6e c2 30 10 bc f7 2b 22 df c9 36 |x..S.n.0...+"..6|
39 54 15 72 c2 ad 3f 40 39 57 c6 5e 07 43 fc 50 |9T.r..?@9W.^.C.P|
6c 1e fd fb 6e 4a 02 04 54 a9 67 2c 59 9e 9d f5 |l...nJ..T.g,Y...|
8e 77 56 32 5f 9c 6c 9b 1d b0 8b c6 bb 8a 15 f9 |.wV2_.l.........|
2b cb d0 49 af 8c 6b 2a b6 fa fc 98 bd b3 45 fd |+..I..k*......E.|
92 d1 e2 27 15 e6 b4 33 aa 70 b1 47 15 db a4 14 |...'...3.p.G....|
e6 00 2e e6 42 f9 35 e6 d2 5b a0 04 b0 73 09 15 |....B.5..[...s..|
a1 aa 77 22 08 0e 04 46 4e 7a a7 4d 43 3a 92 84 |..w"...FNz.MC:..|
2e 22 c7 e3 31 b7 46 76 3e 7a 9d 72 df 35 10 e5 |."..1.Fv>z.r.5..|
06 ad 80 93 34 50 e6 6f 57 51 92 08 1d 46 74 e9 |....4P.oWQ...Ft.|
ca f4 9c d2 b7 31 31 83 af ba e0 30 c2 e9 05 bd |.....11....0....|
55 bb 36 8a ad f6 2a fc 1e 61 ab e8 5a ad 39 fc |U.6...*..a..Z.9.|
95 9a 0a 18 97 b0 13 32 99 03 f6 af dc 86 b7 ad |.......2........|
Enviado por jesparza el Mar, 2012/01/24 - 21:49.
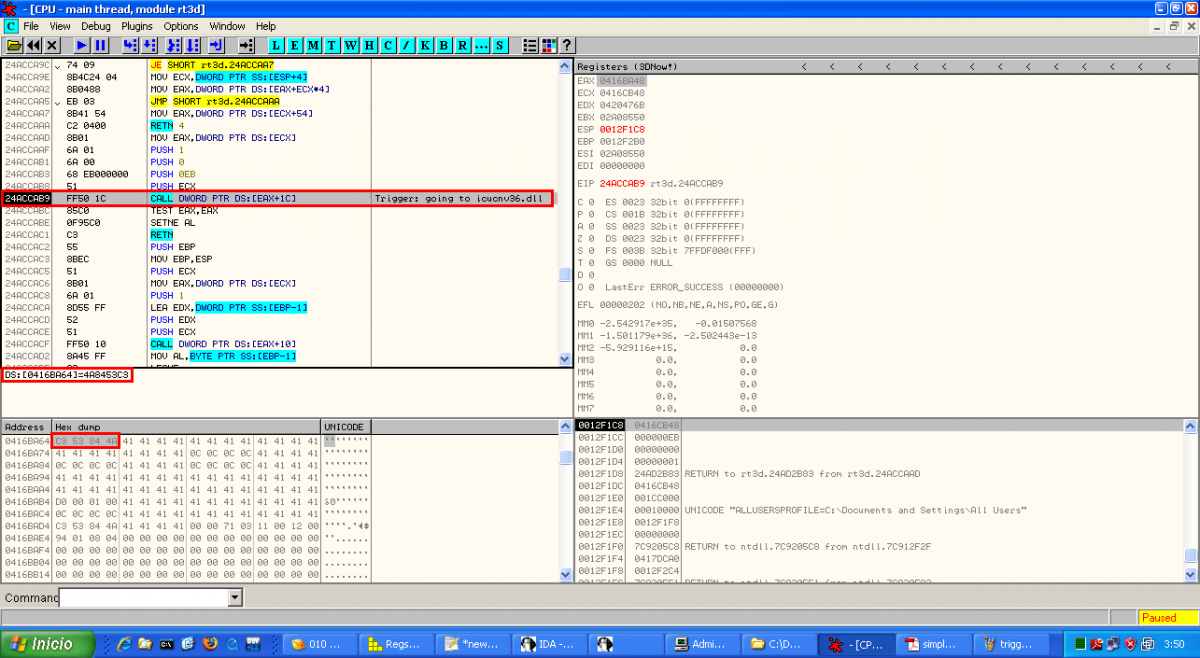
After the exploit static analysis some things like the function of the shellcode were unclear, so a dynamic analysis could throw some light on it. When we open the exploit without the Javascript code used for heap spraying we obtain an access violation error in rt3d.dll. If we put a breakpoint in the same point when we launch the original exploit we can see this ( better explanation of the vulnerability):
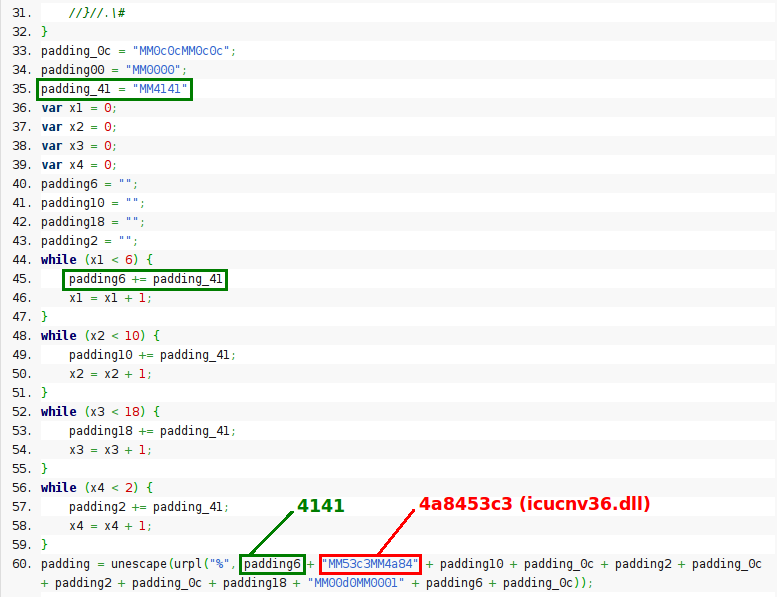
Instead of showing an access violation the CALL function is pointing to a valid address in icucnv36.dll, 0x4A8453C3. This address is not random and it's used in the Javascript code to perform part of the heap spraying:
Enviado por jesparza el Lun, 2012/01/23 - 17:30.
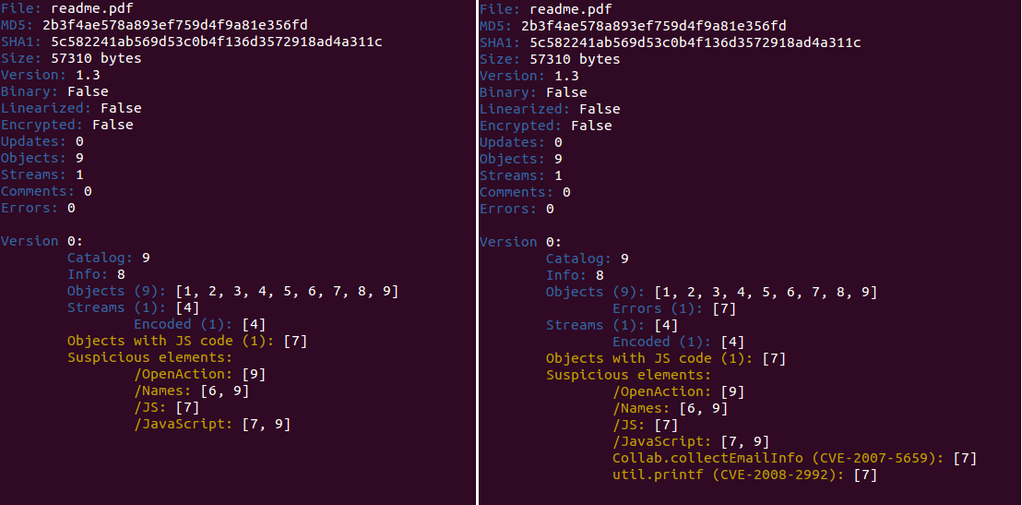
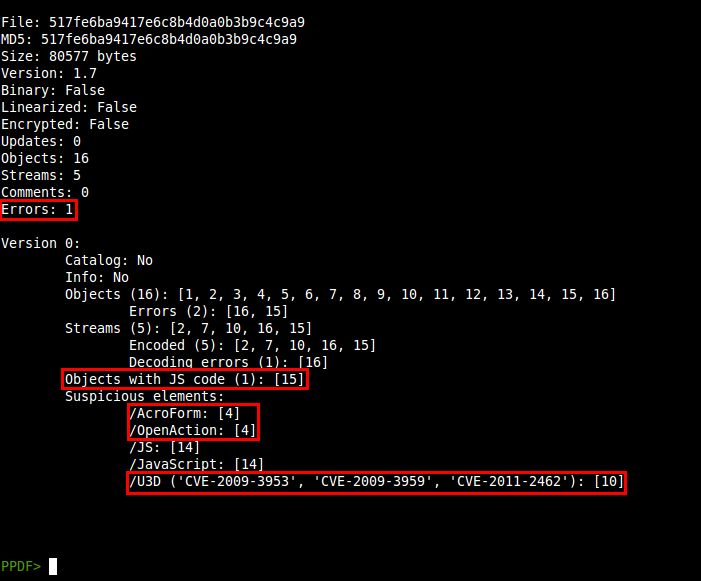
CVE-2011-2462 was published more than one month ago. It's a memory corruption vulnerability related to U3D objects in Adobe Reader and it affected all the latest versions from Adobe (<=9.4.6 and <= 10.1.1). It was discovered while it was being actively exploited in the wild, as some analysis say. Adobe released a patch for it 10 days after its publication. I'm going to analyse a PDF file exploiting this vulnerability with peepdf to show some of the new commands and functions in action.
As usual, a first look at the information of the file:
I've highlighted the interesting information of the info command: one error while parsing the document, one object (15) containing Javascript code, one object (4) containing two ways of executing elements (/AcroForm, /OpenAction) and one U3D object (10), suspicious for its known vulnerabilities, apart of the latest one.
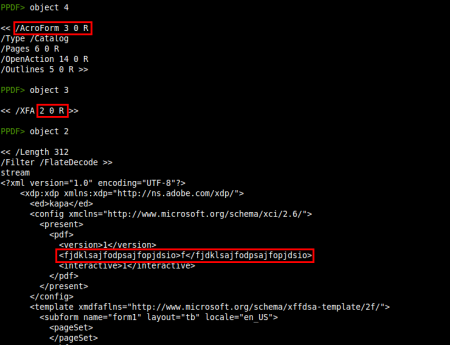
So we have several objects to explore, let's start from the /AcroForm element (object 4):
Enviado por jesparza el Lun, 2012/01/16 - 18:22.
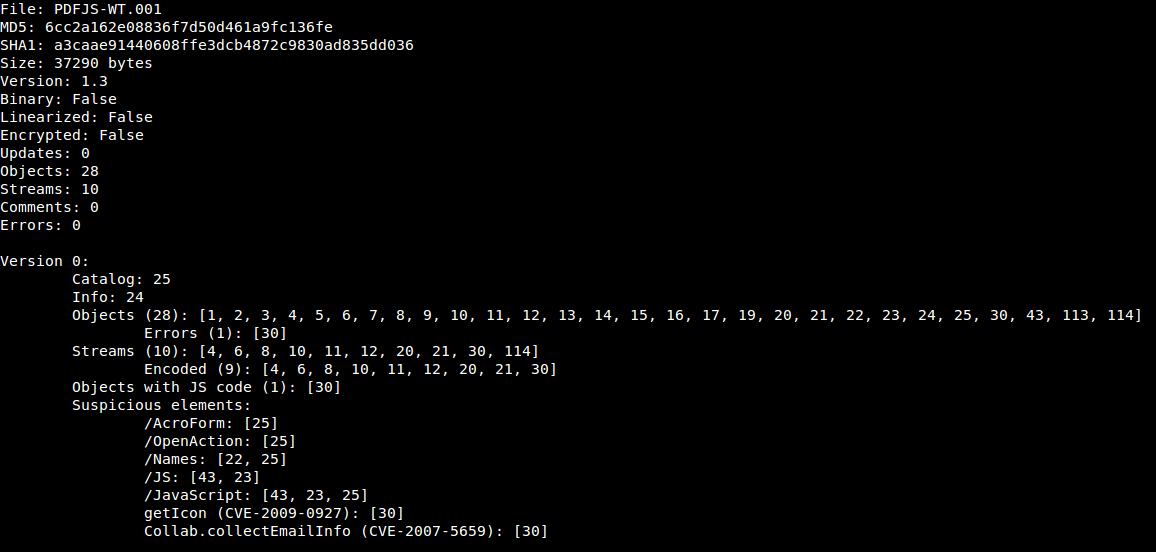
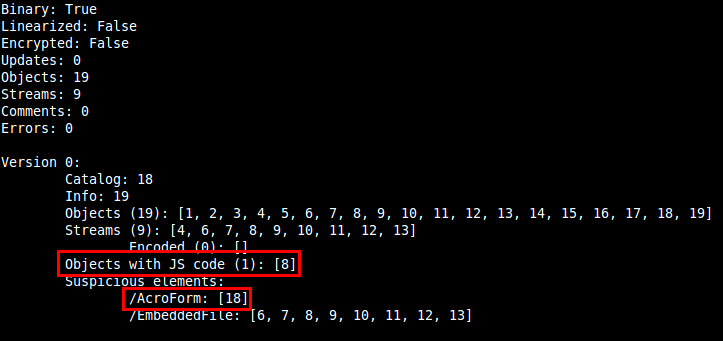
According to a Kaspersky Lab article, SEO Sploit Pack is one of the Exploit Kits which appeared in the first months of the year, being PDF and Java vulnerabilities the most used in these type of kits. That's the reason why I've chosen to analyse a malicious PDF file downloaded from a SEO Sploit Pack. The PDF file kissasszod.pdf was downloaded from hxxp://marinada3.com/88/eatavayinquisitive.php and it had a low detection rate. So taking a look at the file with peepdf we can see this information: In a quick look we can see that there are Javascript code in object 8 and that the element /AcroForm is probably used to execute something when the document is opened. The next step is to explore these objects and find out what will be executed:
Enviado por jesparza el Lun, 2011/11/14 - 01:03.
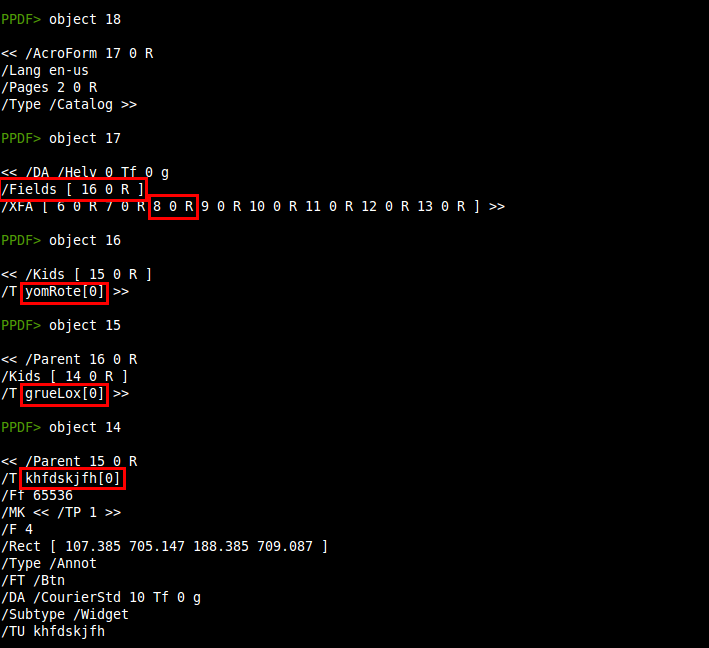
Después de analizar los objetos que nunca se ejecutarían, ahora podemos centrarnos en los que sí que serán procesados por los lectores PDF: /Catalog (27)
dictionary (28)
dictionary (22)
dictionary (23)
dictionary (22)
/Annot (24)
dictionary (23)
/Page (25)
/Pages (26)
/Page (25)
stream (21)
/Pages (26)
Si echamos un vistazo al objeto Catalog:
PPDF> object 27
<< /AcroForm 28 0 R
/MarkInfo << /Marked true >>
/Pages 26 0 R
/Type /Catalog
/Lang en-us
/PageMode /UseAttachments >>
No se ve ningún trigger en este objeto (/OpenAction) ni en el resto de objetos (/AA), así que dirigimos nuestras sospechas hacia el elemento /AcroForm, otra forma de ejecutar código al abrir un documento PDF. Además, el objeto 21, que aparecía como sospechoso (/EmbeddedFile), también está relacionado con el formulario interactivo encontrado (/AcroForm):
Enviado por jesparza el Mar, 2011/07/26 - 21:30.
El pasado mes de noviembre, The Honeynet Project publicó un nuevo reto, esta vez sobre el análisis de un archivo PDF malicioso. Aunque es un poco antiguo ya, voy a analizarlo con peepdf porque creo que tiene algunas cosas interesantes y peepdf hace el análisis un poco más fácil. El archivo PDF se puede descargar desde aquí.
Lanzando peepdf sin ninguna opción obtenemos el siguiente error:
$ ./peepdf.py -i fcexploit.pdf
Error: parsing indirect object!!
Se trata de un error durante el proceso de "parseo". Cuando analizamos archivos maliciosos es muy recomendable usar la opción -f para ignorar este tipo de errores y continuar con el análisis:
$ ./peepdf.py -fi fcexploit.pdf
File: fcexploit.pdf
MD5: 659cf4c6baa87b082227540047538c2a
Size: 25169 bytes
Version: 1.3
Binary: True
Linearized: False
Encrypted: False
Updates: 0
Objects: 18
Streams: 5
Comments: 0
Errors: 2
Version 0:
Catalog: 27
Info: 11
Enviado por jesparza el Mar, 2011/07/26 - 00:19.
Hace ya más de dos meses que hablé en la Rooted CON (Madrid) sobre diferentes técnicas para ocultar y ofuscar archivos PDF maliciosos. El viernes pasado volví a realizar la misma presentación en el CARO 2011 (Praga), aunque actualizando los datos y con demo de peepdf incluida.
La idea es usar ciertas malformaciones de los documentos, comentadas en las ponencias de Julia Wolf, y la propia especificación del formato PDF para evitar que los motores antivirus y los parsers de PDFs lleguen a encontrar el contenido malicioso. Para esta tarea hay que tener en cuenta diferentes aspectos de la estructura de este tipo de documentos y mezclarlos para obtener el deseado archivo no detectado. Algunas de las más importante son las siguientes:
Enviado por jesparza el Vie, 2011/05/13 - 15:09.

|