Como ya comenté en mi post anterior, hace unos días se publicó la primera versión de peepdf. Se trata de una herramienta escrita en Python y enfocada al análisis de archivos PDF, por lo que su objetivo principal es el discernir si un documento PDF es malicioso o no. Se presenta inicialmente con una interfaz de consola interactiva donde se pueden ejecutar diferentes comandos para recabar información acerca del archivo. La idea es no tener que usar múltiples herramientas para decodificar objetos, analizar código Javascript o la shellcode, sino usar únicamente una herramienta (con sus wrappers) para el análisis de PDFs. También podéis encontrar la herramienta en la última versión de la distribución BackTrack (¡gracias al equipo de BackTrack!).
Las principales funcionalidades de peepdf son las siguientes:
Análisis
Decodificación: hexadecimal, octal, objetos name
Implementación de los filtros más usados
Referencias en objetos
Listado de objetos donde se referencia a otro objeto
peepdf is a Python tool to explore PDF files in order to find out if the file can be harmful or not. The aim of this tool is to provide all the necessary components that a security researcher could need in a PDF analysis without using 3 or 4 tools to make all the tasks. With peepdf it's possible to see all the objects in the document showing the suspicious elements, supports the most used filters and encodings, it can parse different versions of a file, object streams and encrypted files. With the installation of PyV8 and Pylibemu it provides Javascript and shellcode analysis wrappers too. Apart of this it is able to create new PDF files, modify existent ones and obfuscate them.
Después de un año repleto de incidentes relacionados con el Portable Document Format (PDF) está bien mirar atrás y recordar algunos de los más importantes. A continuación se enumeran los enlaces de análisis de documentos PDF maliciosos y/o ofuscados, así como algunas herramientas que han hecho aparición en 2010. Espero que las disfrutéis! ;)
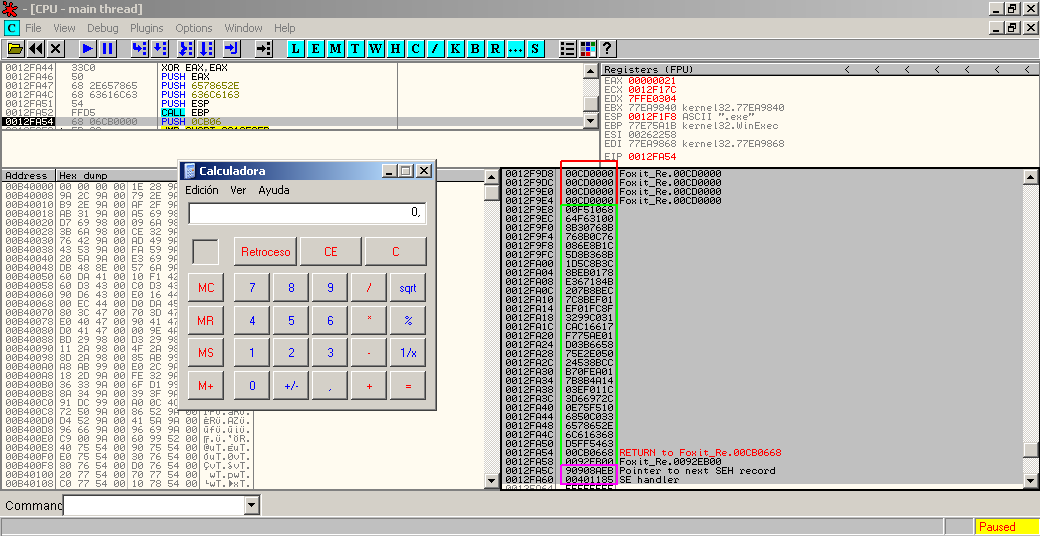
After the Jailbreakme PDF vulnerability explanation I'm gonna publish the proof of concept of the same vulnerability for Foxit Reader. This is a patched vuln for this product so I suppose there will be no problem with that. Like I said, we can use a 116-bytes shellcode without the necessity of another exploiting stage, so I've modified this calc.exe shellcode for this PoC.
This exploit generates a PDF file which can be used against Foxit Reader in Windows XP and Windows Vista. This is functional only for the latest versions of Foxit Reader but it's very easy to modify it for other ones (there is an example in the exploit for the 3.0). You can find the python script in the Exploits section or directly here. Enjoy it!! ;)
Today has been released the source code of the Jailbreakme exploit, so maybe this explanation comes a bit late. In the update of the previous post about this subject I knew that I was right about the overflow in the arguments stack when parsing the charstrings in the Type 2 format, so here is a little more info.
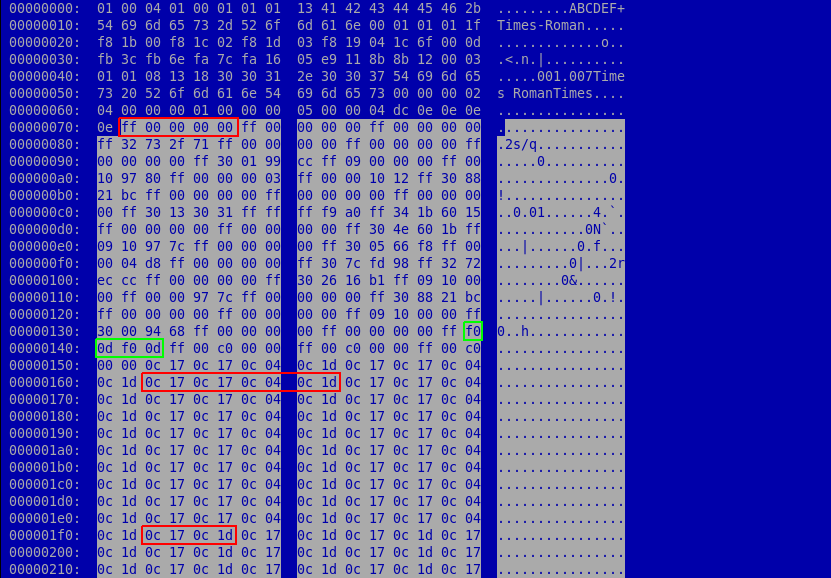
After decoding the stream of the object 13 we can see the following bytes (talking about this file):
The selected bytes are the important ones for this exploit because the overflow occurs when parsing them. Like I mentioned, the Type 2 format is composed of operands, operators and numbers, and use the stack to push and pop values. This stack has a maximum size of 48 elements. We can understand better the meaning of these bytes with this tips:
Some days ago Comex published his JailbreakMe for the new iPhone 4 in the Defcon 18. The interesting thing is that in order to root the device he used a PDF exploit for Mobile Safari to execute arbitrary code and after this another kernel vuln to gain elevated privileges. I've being taking a look at the PDF files with peepdf and these are my thoughts about it.
The PDF file itself has no many objects and only one encoded stream:
The stream is encoded with a simple FlateDecode filter, without parameters, and if we decode its content we can see this strings, related to the JailbreakMe stuff:
As this object seems to contain the vulnerability we are looking for we'll take a closer look to this stream and what this is for:
Description: Script to analyze malicious PDF files containing obfuscated Javascript code. It uses Spidermonkey to execute the found Javascript code and showing the shellcode to be launched. Sometimes it's not able to deobfuscate the code, but you can specify the parameter -w to write to disk the Javascript code, helping to carry out a later manual analysis. Its output has five sections where you can find trigger events (/OpenAction and /AA), suspicious actions (/JS, /Launch, /SubmitForm and /ImportData), vulnerable elements, escaped bytes and URLs, which can be useful to get an idea of the file risk.
Description: This script compress/decompress a specified string or file using the Zlib library and writes to the standard output. If the input is a file and the method used is decompression, then the script looks for the streams compressed with the /FlateDecode filter, so it's focused on PDF files. If there is no filters in the file, the whole file is considered as a stream.
ZeuS sigue en boca de todos, se descarga con falsos antivirus y downloaders, con diferentes exploit kits, y la red social por excelencia no podía ser una excepción. La semana pasada se vieron en Facebook mensajes como el siguiente:
La URL contenida en el mensaje llevaba a un sitio de phishing de Facebook donde se pedía la autenticación en el sistema, a la vez que se ejecutaba código Javascript ofuscado que creaba un iframe oculto en el cuerpo de la página:
La página a la que redirigía el iframe contenía a su vez otros dos iframes:
As I mentioned before, one of the ways to hide information in a PDF file is trough the encoding/compression of streams, thanks to filters (/Filter parameter), being /FlateDecode the most used. The bad guys have been using it some time ago to hide obfuscated Javascript code with some vulnerable functions (Collab.collectEmailInfo, util.printf, getAnnots, getIcon, spell.customDictionaryOpen), or using heap-spraying to exploit another vulnerability not related with Javascript, like the /JBIG2Decode filter one.
To help in the analysis of these malicious files I've written a mini Python tool, using Spidermonkey to execute the found Javascript code and showing the shellcode to be launched. Automating the execution of obfuscated Javascript code is not a simple issue because there are many ways of doing it and everyday a new one arises, so I've tried to do an approximation to the problem, thanks to the malicious samples that I've seen. In the case the script won't be able to go till the end it's possible to specify the parameter -w to write to disk the Javascript code, helping to carry out a later manual analysis.
I'm gonna stop writing about actions in PDFs to begin with the filters that can be applied to the streamobjects. An stream object is composed by a dictionary followed by the real content between the words stream and endstream. Within this dictionary are defined the stream properties like size, filters to apply in order to decode/decompress it or the file name in the case of the stream is located in an external file.
As you suppose, a way to hide information in a PDF file is applying to it one or more filters in order to avoid identifying it easily and putting it hard to extract the real content. In fact this is an usual technique in most of the malicious files that try to exploit some of the latest vulnerabilities.
As I mentioned some time ago we wan perform several actions with a PDF file. One of them is application execution, which we can use on different platforms like Windows, Unix or Mac.In order to check the potential of this functionality I'm going to modify a basic PDF. First of all we must include an action trigger, when we open the document, for example. For this task we have to put an /OpenAction element in the document catalog, pointing to an object that will be the /Launch action which will execute the desired application. The action object can include the following elements:
Before I continue with the different actions we can perform within a PDF file I'm gonna create a simple PDF file which we can modify easily. If you open a PDF with any text editor you'll see a lot of objects and elements that can confuse you a bit. In order to avoid this let's make a PDF document from scratch with a text editor, without all the unnecessary elements.
We must begin knowing which of the PDF elements are obligatory and must be present in our file. I've written some weeks ago about the physic and logic structure of these types of documents so I'll only enumerate what we'll need:
The PDF format is becoming more and more (in)famous due to the lately published vulnerabilities in Adobe products allowing the execution of arbitrary code in the system. Now I don't want to write about these malicious files but I'll do it in future posts.
After the brief comments about the objects we can find in a document of this type and its physic and logic structure I'm going to follow with the actions that can be executed in background. The PDF files aren't static documents but it's possible to specify some kind of programming depending on the user actions. This is where the security problem arises and that becomes a simple PDF in a potential malcode with high probabilities of being executed.
A PDF action is a dictionary object which can contain the following elements:
/Type: it's optional and it's used to specify the object type of the dictionary. In this case it's Action.
/S: it's an obligatory element that defines the type of the action we want to do.
/Next: it's optional too and specifies the next action or actions to be executed.
Some months ago in the Black Hat Europe, Eric Filiol gave a talk about the functionalities of the PDF format. Filiol said that thanks to some features a simple PDF could become malcode executing the attacker instructions. Besides this, the exploitation of vulnerabilities in this type of documents is more and more usual nowadays. This is why I'm going to write about the basics of the PDF structure and how it works internally. Maybe this can be boring but I promise you that next posts about this subject will be more practical;) To make it more enjoyable you can open a PDF file in a text or hexadecimal editor and take a look at what I mention in the next paragraphs.
A PDF file consist of multiple objects connected between them. This objects can belong to one type from eight possible values: boolean, integer and real numbers, text strings, names, arrays, dictionaries, streams and nulls. Apart of the "known" types, names are a kind of tag for the different elements that compose an object, dictionaries, delimited by "<<" and ">>", are a collection of pairs key-value, and streams, delimited by "stream" and "endstream", are bytes sequences, an information flow that the PDF readers can read incrementally, unlike the normal text strings. All the objects can be declared as indirect objects, assigning them an id to be referenced in any part of the file. This type of objects are delimited by the words "obj" and "endobj".
The physic structure of a PDF file is divided in header, body, cross references table and trailer: