peepdf v0.1: nueva herramienta de análisis y modificación de archivos PDF |
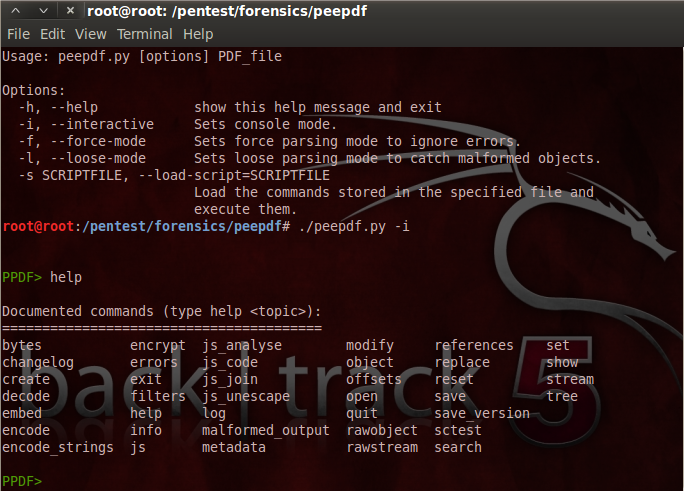
Las principales funcionalidades de peepdf son las siguientes:
Análisis
- Decodificación: hexadecimal, octal, objetos name
- Implementación de los filtros más usados
- Referencias en objetos
- Listado de objetos donde se referencia a otro objeto
- Búsqueda de cadenas de texto y bytes (incluidos streams y objetos cifrados)
- Estructura física (offsets)
- Estructura lógica
- Metadatos
- Modificaciones entre versiones (changelog)
- Análisis de objetos comprimidos (object streams)
- Análisis y modificación de Javascript (Spidermonkey): unescape, replace, join
- Análisis de shellcodes (wrapper de sctest, Libemu)
- Uso de variables (comando set)
- Extracción de versiones antiguas del documento
Creación/Modificación
- Creación de un PDF básico
- Creación de un PDF con ejecución de Javascript cuando el archivo se abre
- Creación de object streams para comprimir objetos
- Embeber archivos (incuyendo otros documentos PDF)
- Ofuscación de objetos de tipo name y string
- Salida mal formada de PDFs: sin endobj, basura en la cabecera, corromper la cabecera...
- Modificación de filtros
- Modificación de objetos
./peepdf.py -s archivo_de_comandos.txt sample.pdf
Por último, si solo queremos conocer información sobre los objetos, streams, si contiene Javascript y vulnerabilidades, sin lanzar más comandos, bastaría con ejecutarla de esta forma:
./peepdf.py sample.pdf
En todas las formas de ejecución se pueden especificar dos parámetros bastante útiles de cara a proseguir con el análisis cuando se encuentran errores y tratar con objetos mal formados:
- -f: ignora los errores que se puedan producir y continúa con el análisis del documento. Muy útil al analizar documentos maliciosos.
- -l: no busca los tags de final de objeto al parsear los objetos, por lo que es útil cuando un documento contiene objetos mal formados.
Próximamente intentaré publicar algunos ejemplos de análisis de archivos PDF maliciosos con esta herramienta para clarificar un poco más su uso. Mientras tanto, si os interesa podéis echar un vistazo a la página del la herramienta. Como ya dije, ¡cualquier comentario y posible bug es bienvenido!
UPDATE (23/06/2011): Se ha incluido más documentación en la página del proyecto en Google Code sobre cómo instalar y ejecutar la herramienta, así como una explicación detallada de cada comando de la consola.