New version of peepdf (v0.1 r92 - Black Hat Europe Arsenal 2012) |
Last week I presented the last version of peepdf in the Black Hat Europe Arsenal. It was a really good experience that I hope I can continue doing in the future ;) Since the very first version, almost one year ago, I had not released any new version but I have been frequently updating the project SVN. Now you can download the new version with some interesting additions (and bugfixes), and take a look at the overview of the tool in the slides. I think it's important to mention that the version included in the Black Hat CD and the one in the Black Hat Arsenal webpage IS NOT the last version, this IS the last version. I've asked the Black Hat stuff to change the version on the site so I hope this can be fixed soon.

So I'm going to enumerate the new features in this version of "the Swiss army knife of PDF security apps" (I don't know who wrote that but I love it!):
- Improved PDF filters: I've added the implementation of LZWDecode and ASCII85Decode from pdfminer by Yusuke Shinyama to avoid parsing errors because I think it's better code than the used in the last version. I have also included a better support for predictor parameters of FlateDecode and LZWDecode filters. Thanks to Brandon Dixon to report related bugs! ;)
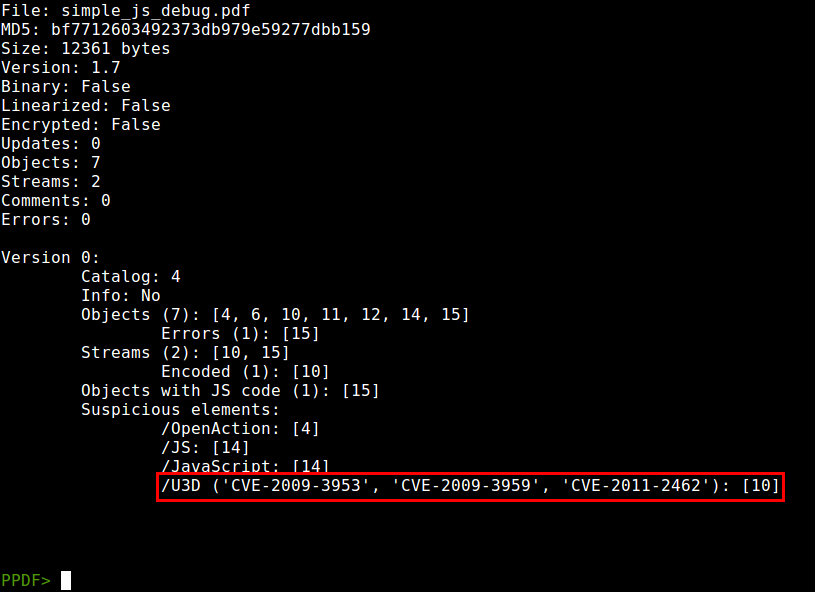
- New vulnerabilities: Added new monitorization of vulnerabilities related to doc.printSeps function (CVE-2010-4091), /U3D objects (CVE-2009-3953, CVE-2009-3959, CVE-2011-2462) and /PRC objects (CVE-2011-4369).
- Updating process: The option of updating the tool from the command line has been added. When the tool is executed with the -u option the latest version of the files in the repository are checked and compared with the local files, updating as needed.
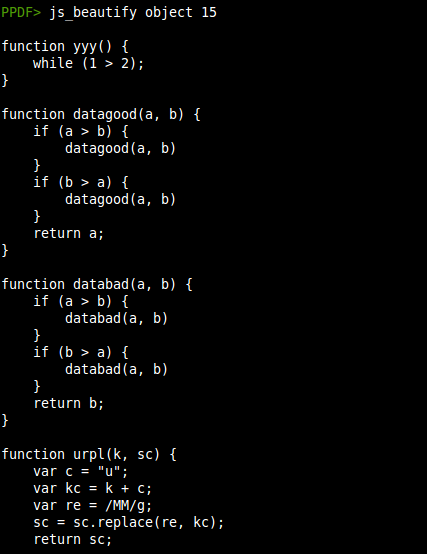
- Javascript beautifier: Thanks to the code from jsbeautifier.org a new command (js_beautify) to beautify the Javascript output has been included.
- Hash command: Now it's possible to make a hash (MD5/SHA1/SHA256) of some elements like objects, raw objects, stream, raw streams, raw bytes, files and variables. Thanks to @bingo for the petition and code! ;)
- Easy extraction of information: As I mentioned some weeks ago, now it's very straightforward to extract information from any command thanks to the redirection in the console (>, >>, $>, $>>).
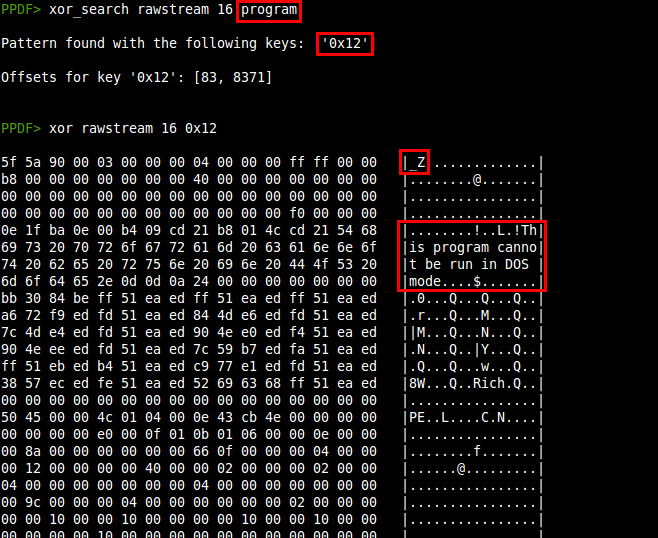
- New commands to perform XOR operations: Two commands (xor and xor_search) have been included to perform XOR operations to objects, raw objects, stream, raw streams, raw bytes, files and variables. The xor command performs a simple XOR with the given key or brute-forcing if it's not specified. xor_search searches the result of XOR brute-forcing for the given pattern. You can find an example of use in this article.
- XML output: Added the -x option to obtain an XML output of the file containing the same information as the basic execution, useful for automatic analysis. The DTD file can be found here.
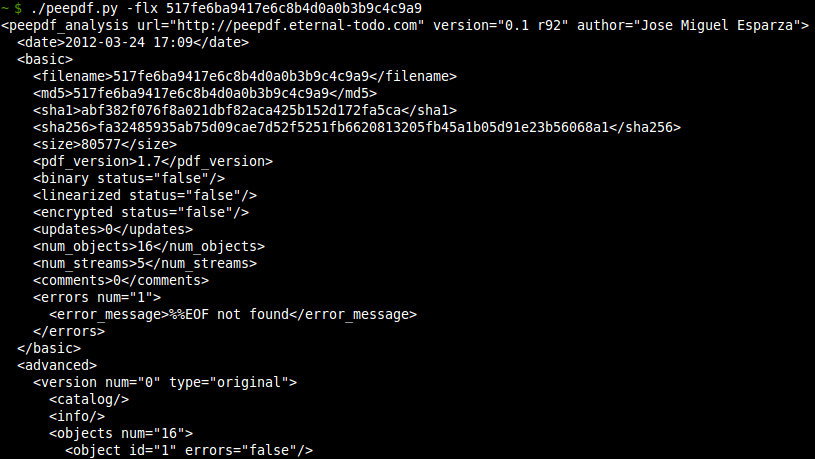
You can find the complete changelog here. I hope these changes can help you in your daily PDF analysis and I expect comments / bugs / new features to continue improving the tool ;) Thanks!!
Impressive Source Code
The source code looks quite good. I'm especially impressed by the lzw decoder and crypto. spidermonkey is also an interesting library to put to use. Do you feel that there should be a security concern about running this automatically on all PDF files?
Re: Impressive Source Code
Hi!
Thanks for the comments! But the LZW decoder is code from a third-party library, hehe ;) What do you mean by "security concern"? Do you mean executing peepdf automatically with any kind of PDF files? Nop, no security issues related to the PDF exploits at least...
Cheers!
Jose