One week before my demo at the Black Hat Arsenal I released a peepdf challenge. The idea was solving the challenge using just peepdf, of course ;) This post will tell you how to solve the challenge so if you want to try by yourself (you should!) STOP READING HERE! The PDF file can be downloaded from here and it is not harmful. No shellcodes, no exploits, no kitten killed. In summary, you can open it with no fear, but do it with a version of Adobe Reader prior to XI ;)
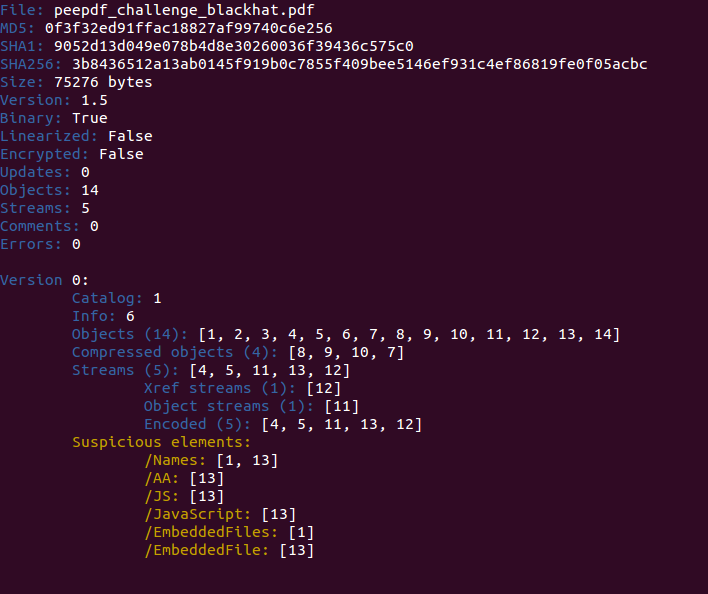
Let's start! :) This is what you see with the last version of peepdf:
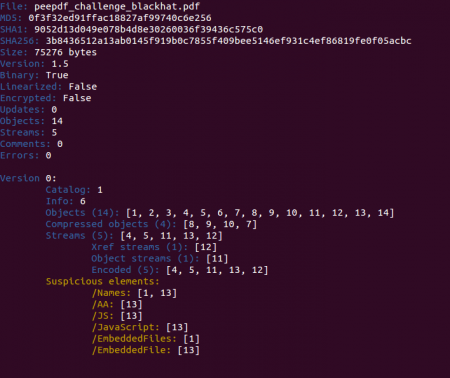
In a quick look you can spot some Javascript code located in object 13 and also an embedded file in the same object. Checking the references to this object and some info about it we see that it is an embedded PDF file: