Adding a scoring system in peepdf |
Just before the summer I announced that the student Rohit Dua would dedicate his time to improve peepdf and add a scoring system to the output. This was possible thanks to Google and his Google Summer of Code (GSoC) program, where I presented several projects as a member of The Honeynet Project. A beta version was presented during Black Hat Europe Arsenal 2015 last November, where I introduced the new functionalities.
The scoring system has the goal of giving valuable advice about the maliciousness of the PDF file that’s being analyzed. The first step to accomplish this task is identifying the elements which permit to distinguish if a PDF file is malicious or not, like Javascript code, lonely objects, huge gaps between objects, detected vulnerabilities, etc. The next step is calculating a score out of these elements and test it with a large collection of malicious and not malicious PDF files in order to tweak it.
The scoring is based on different indicators like:
- Number of pages
- Number of stream filters
- Broken/Missing cross reference table
- Obfuscated elements: names, strings, Javascript code.
- Malformed elements: garbage bytes, missing tags…
- Encryption with default password
- Suspicious elements: Javascript, event triggers, actions, known vulns…
- Big streams and strings
- Objects not referenced from the Catalog
Here’s a screenshot of the scoring system in action:
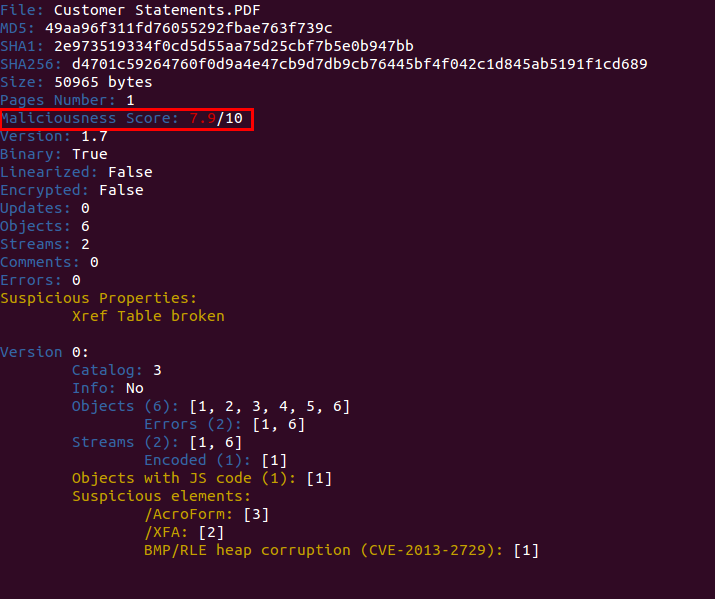
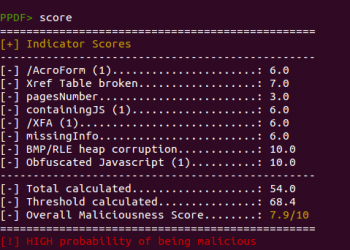
Besides that, a new command was created to show the individual score assigned to the different indicators and give more details about how the global score was calculated. This command is called “score” and this is an example of its output:
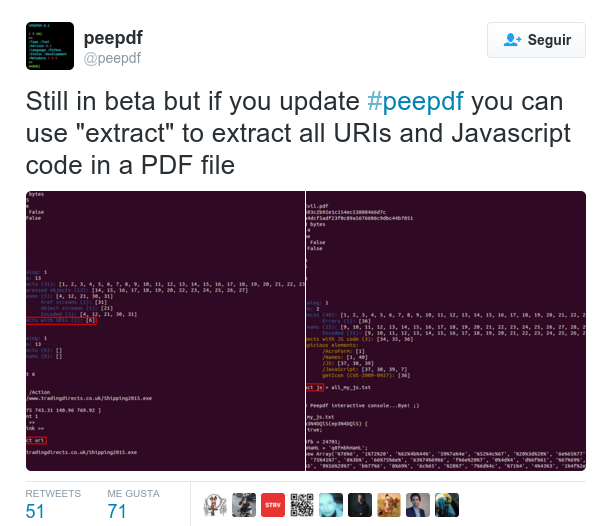
You can try the scoring system checking out the gsoc branch on Github. Some more tests are needed to include it in the master branch, but as soon as I have some free time it will be included for sure. In the next peepdf release the scoring system will be there, but also some other nice features like being able to extract all the Javascript code from the document at the same time or extracting all the URIs present in the document.
This summer peepdf will not be an option in the Google Summer of Code, but there will be really interesting projects if you want to contribute. If you are looking for an interesting summer, take a look at the projects proposed by my Honeynet colleagues, you will not regret it! And stay tuned because the next peepdf release will arrive in a few months :)