Black Hat Arsenal peepdf challenge solution |
One week before my demo at the Black Hat Arsenal I released a peepdf challenge. The idea was solving the challenge using just peepdf, of course ;) This post will tell you how to solve the challenge so if you want to try by yourself (you should!) STOP READING HERE! The PDF file can be downloaded from here and it is not harmful. No shellcodes, no exploits, no kitten killed. In summary, you can open it with no fear, but do it with a version of Adobe Reader prior to XI ;)
Let's start! :) This is what you see with the last version of peepdf:
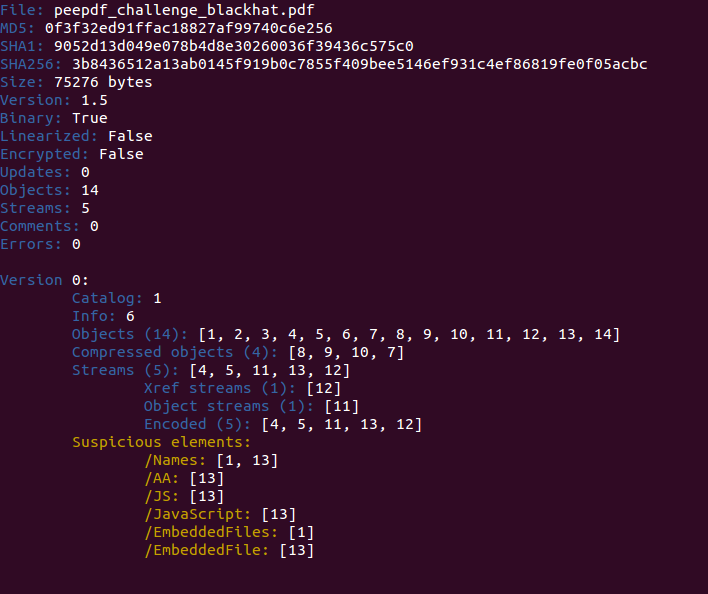
In a quick look you can spot some Javascript code located in object 13 and also an embedded file in the same object. Checking the references to this object and some info about it we see that it is an embedded PDF file:
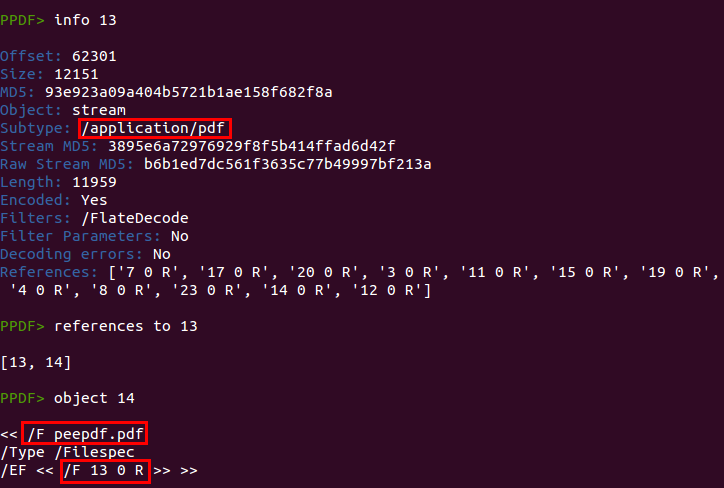
We can easily extract the new PDF file using the following command:
PPDF> stream 13 > peepdf.pdf
If you open this PDF file with the correct versions you will see a popup asking for a “magic code”:
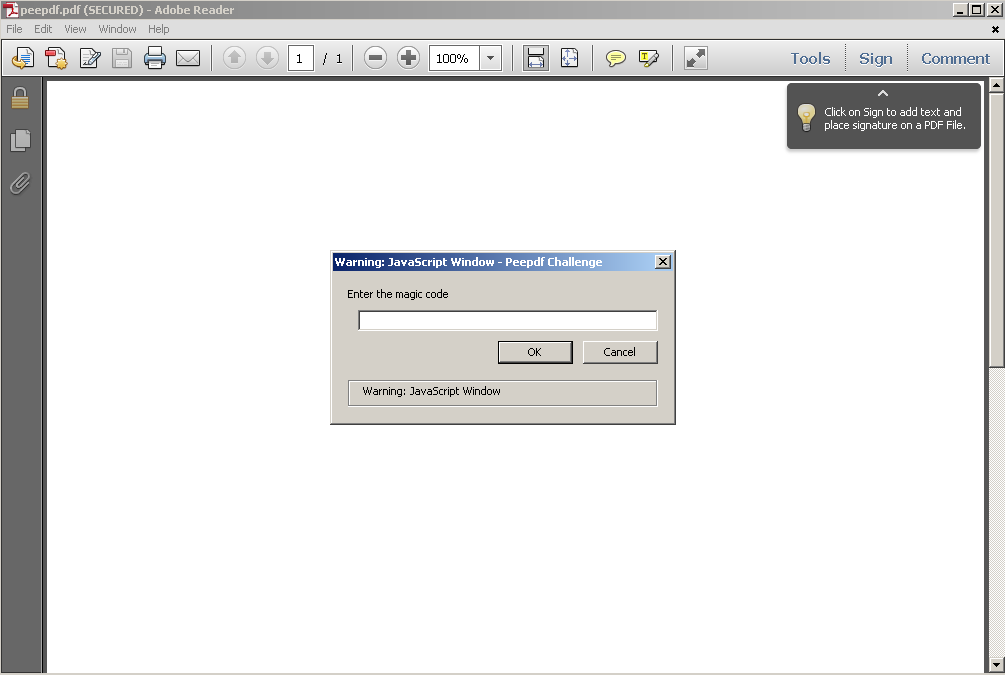
It would be nice if we could find references to “magic” or “code” within the document, but using the search command gives no results (that would be too easy :p). At this point I have to tell you that analyzing the process memory to see if you are lucky is cheating!! This challenge is just about static analysis ;)
This is what you should see after opening this new PDF document with peepdf:
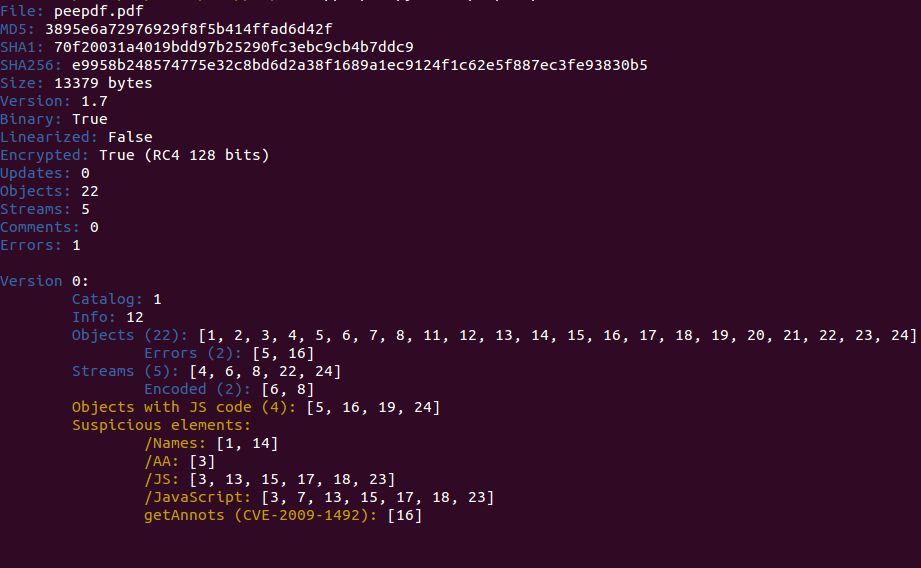
I you open this with an older version you will probably see some errors related to objects 6 and 8. These objects use the /DCTDecode filter which was not supported in previous versions (and it is now). After taking a quick look at the extracted document we can see that it is encrypted using RC4. We can also see two triggers (/AA and /Names) and there are four objects containing Javascript code but six including the /JS name, which can suggest that there are really six objects containing Javascript code. That's easy to check, just exploring those objects:
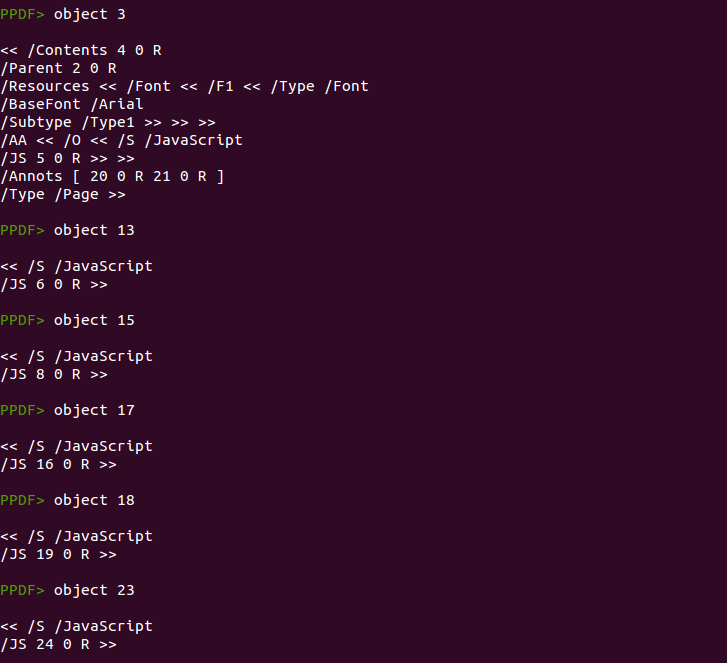
This document has just one page and its properties are described in object 3. There you can see the /AA element triggering some Javascript code located in object 5. This code checks the Adobe Reader version and if it is the correct one executes the function “peepdf” using as argument the value returned from function “r”. At the same time, this function “r” takes two arguments, “a” and the returned value from function “x.d” using “this.info.author” as argument. Clear, right? ;)
var version = app.viewerVersion.toString().split(".")[0];
if (version > 10){
app.alert({cTitle:"Peepdf Challenge",cMsg:"You should try with an older version of Adobe Reader ;)"});
this.closeDoc(true); } else{
peepdf(r(a,x.d(this.info.author)));
}
At this point I would try to search for the functions “peepdf”, “r” and “x.d”. Searching for “r” is useless, too generic. Searching for “x.d” gives no results (except object 5). But searching for “peepdf” returns 5 objects, being object 8 one of them. That is an interesting object...
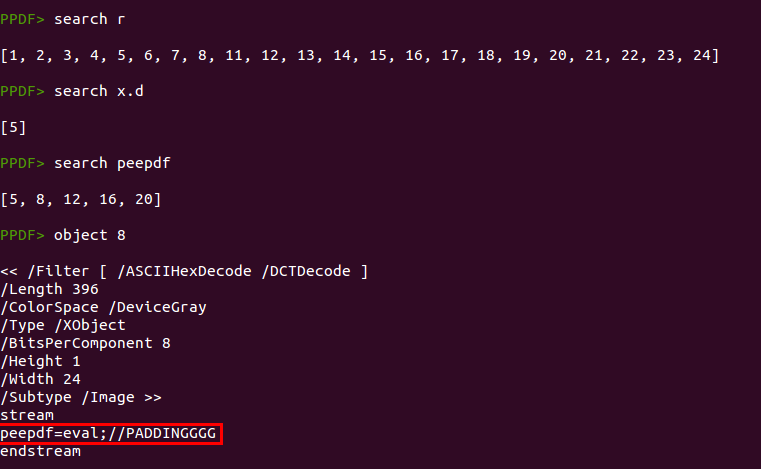
This object is a JPEG image hiding the text “peepdf=eval;//PADDINGGGG” inside. This text can be executed as Javascript as Dénes Óvári explained in his Virus Bulletin blog post, so the “peepdf” function is just the “eval” function. It is important to mention that this object will only appear if you analyze the document with the last version of peepdf which supports the /DCTDecode filter:
Ok, so the next step is exploring the different objects containing Javascript code and see if we can find the missing functions there:
-
Object 6 is another JPEG image hiding the variable “a”
-
var a="QkhQMzNwZGY=";
-
-
Object 19 contains an XOR function where the first argument is the key and the second one is the data to encode/decode.
-
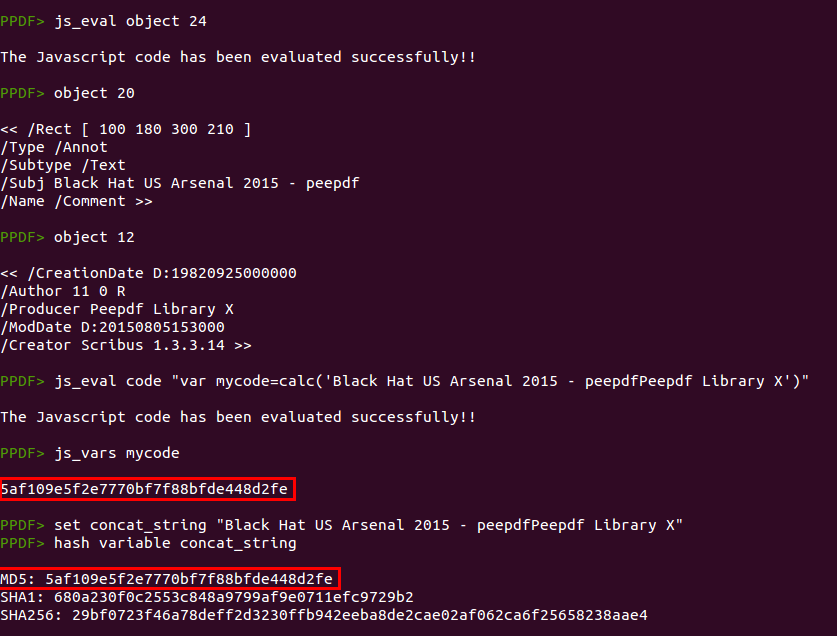
Object 24 contains different functions and a comment mentioning Paul Johnston and this license page. Digging a bit more it is easy to see that the code is derived from the RSA Data Security, Inc. MD5 Message-Digest Algorithm. Yes, just MD5!
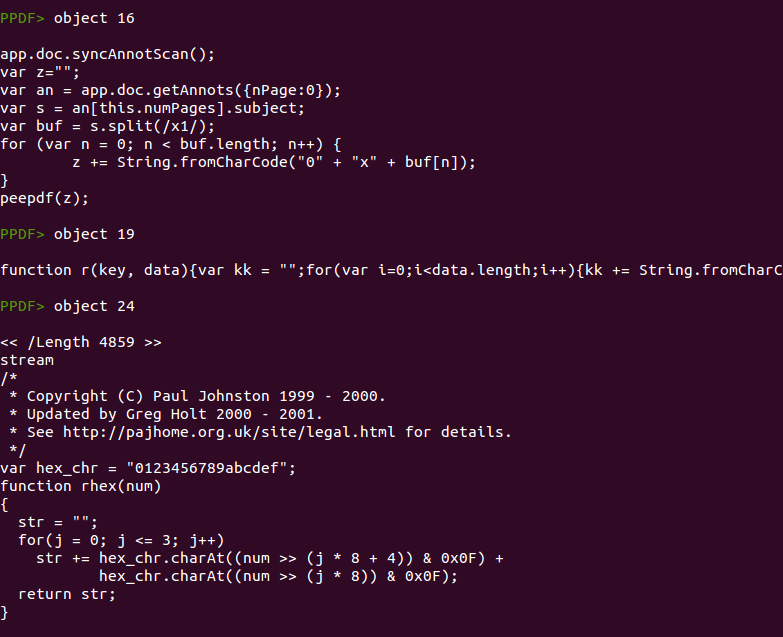
Object 16 deserves its own paragraph. The “getAnnots” function had some security issues in 2009 (CVE-2009-1492) but in this case it is not trying to exploit anything but just getting the annotations found in the page 0 of the document. Then, it will extract the subject content from one of the annotations, using the number of pages as the array index (an[this.numPages].subject). In this case there is one page, so it will retrieve the content of the second annotation (index one is the second array element). If you check again the screenshot showing object 3 you will see that the first annotation is object 20 and the second annotation is object 21, so this code will store in the variable “s” the subject of object 21.
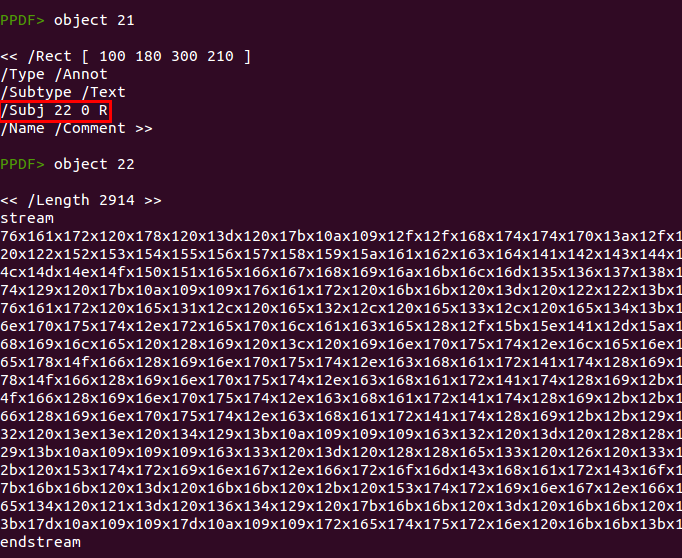
The next thing this code does is splitting the subject content using “x1” to cut it and then convert the resultant hexadecimal array to text and execute it using the function “peepdf” again. You can easily do this in the peepdf console using the stream, replace and decode commands:
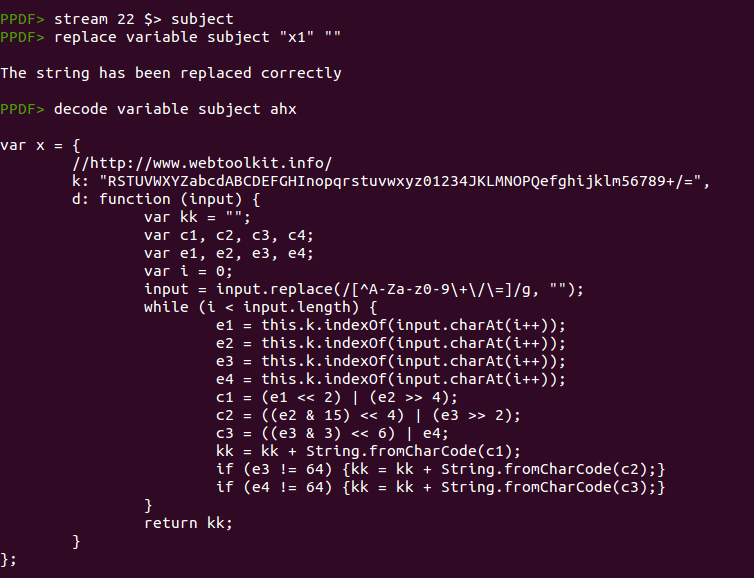
And here we have the “x.d” function! :) We almost have all the elements we need except the “this.info.author” element but this is an easy one. Just exploring the info object is enough:
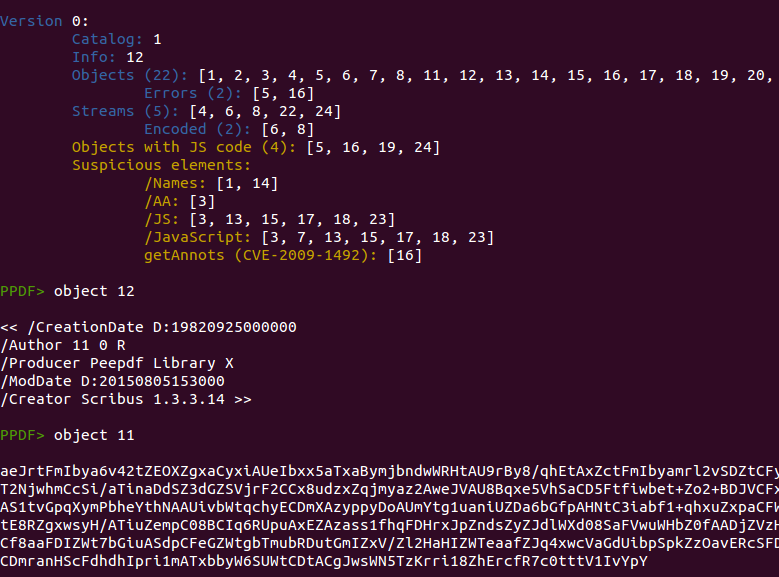
The “info.author” content looks like Base64 and it is because the “x.d” function is really just a Base64 decoder but using a modified alphabet. So let's execute all together! You can write all in a separated file on disk and execute it with “js_eval” from the peepdf console, you can use your favorite Javascript engine or you can do all inside peepdf. Yes, it is possible ;)
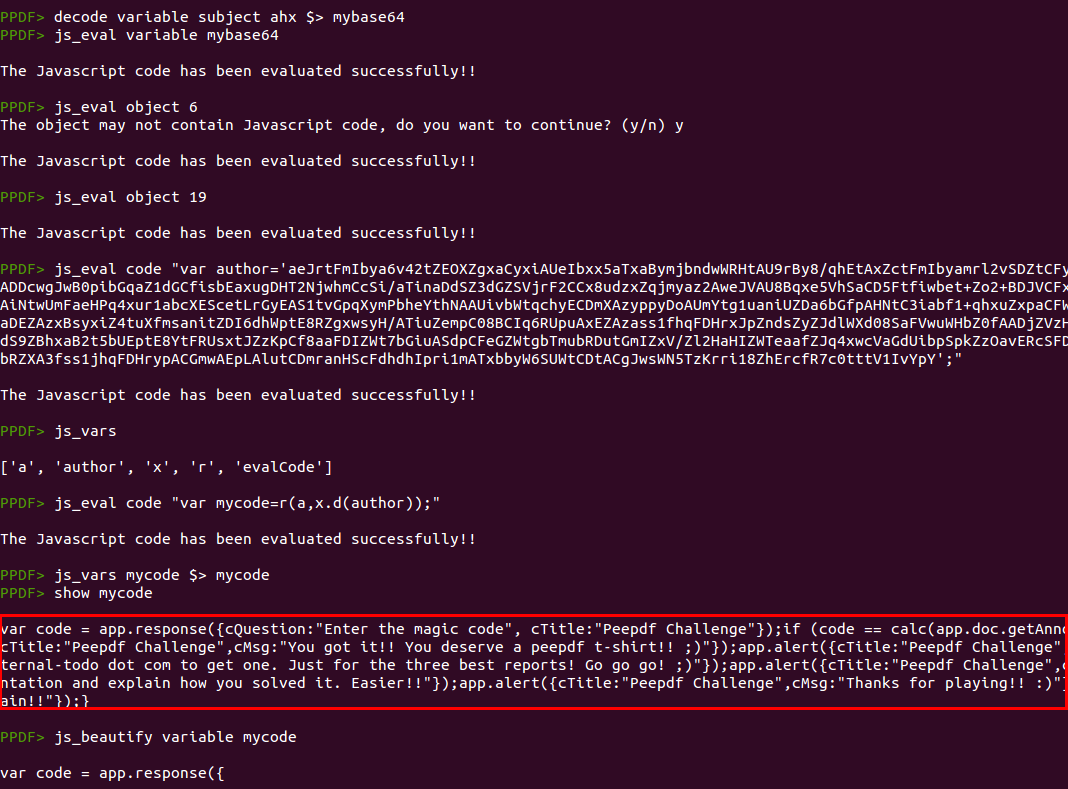
The beautified code is:
var code = app.response({cQuestion: "Enter the magic code",cTitle: "Peepdf Challenge"});
if (code == calc(app.doc.getAnnots({nPage: 0})[0].subject + this.info.producer)) {
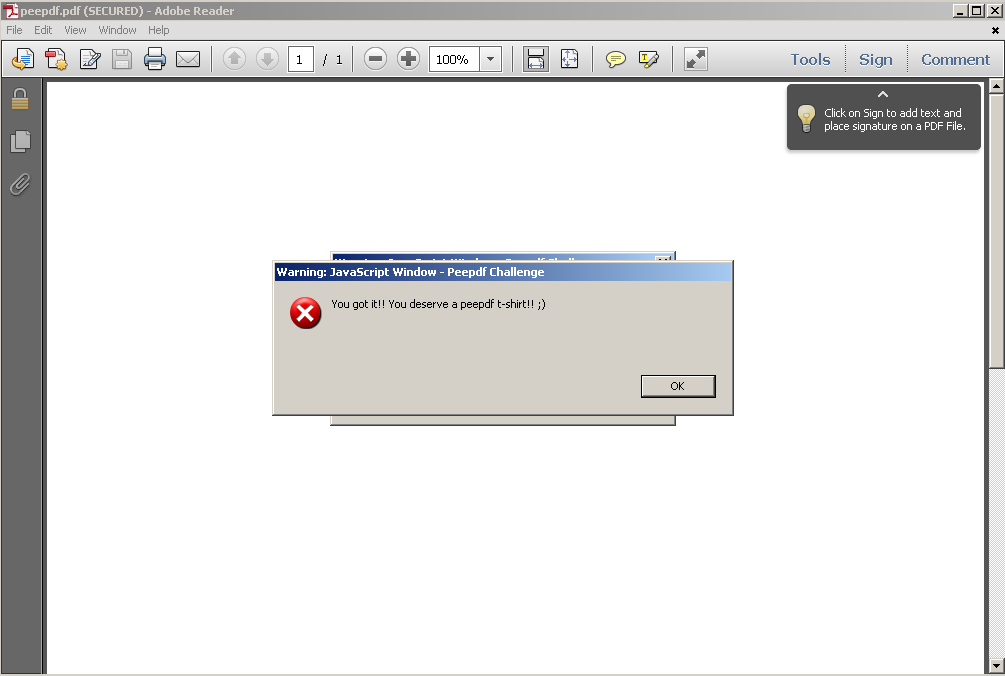
app.alert({cTitle: "Peepdf Challenge",cMsg: "You got it!! You deserve a peepdf t-shirt!! ;)"});
app.alert({cTitle: "Peepdf Challenge",cMsg: "But you need to send a small writeup to peepdf at eternal-todo dot com to get one. Just for the three best reports! Go go go! ;)"});
app.alert({cTitle: "Peepdf Challenge",cMsg: "If you are attending Black Hat just come to my presentation and explain how you solved it. Easier!!"});
app.alert({cTitle: "Peepdf Challenge",cMsg: "Thanks for playing!! :)"});
}
else {
app.alert({cTitle: "Peepdf Challenge",cMsg: "Try again!!"});
}
As you have probably noticed the interesting bit is this condition:
if (code == calc(app.doc.getAnnots({nPage: 0})[0].subject + this.info.producer))
But if you are still reading you probably know how to solve it, right? We need to execute the "calc" function (object 24) passing the concatenation of the subject of the first annotation and the “info.producer” and we will have the magic code ;)
The objective was using just peepdf to solve this challenge and this is how you can do it ;) Some people sent their response/writeup to solve the challenge so I am pleased to announce that the happy winners of a peepdf t-shirt are:
-
Stefano Antenucci (Antelox)
I will send you the t-shirt soon! Thanks a lot to all the participants and thanks for taking the time to write your response and send it to me. I hope you enjoyed this challenge :) I want to thank Ange Albertini too for his tips to compress and hide the Javascript code in the JPEG images. He saved me the time I did not have one week before Black Hat ;)