In past November The Honeynet Project published
a new challenge, this time related to PDF files. Although it's quite old I'm going to analyse it with my tool because I think it has some interesting tricks and
peepdf makes the analysis easier. The PDF file can be downloaded
from here.
If we launch peepdf we obtain this error:
$ ./peepdf.py -i fcexploit.pdf
Error: parsing indirect object!!
It seems that there is an error in the parsing process. Talking about malicious PDF files it's recommended to add the -f option to ignore this type of errors and continue with the analysis:
$ ./peepdf.py -fi fcexploit.pdf
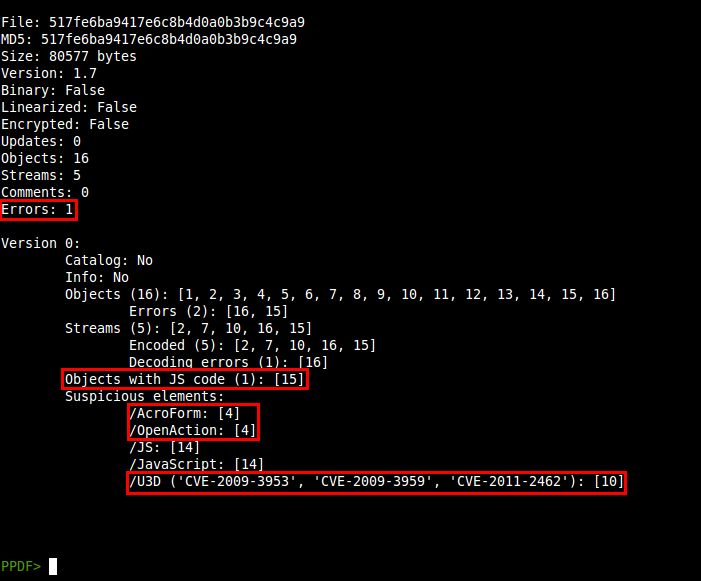
File: fcexploit.pdf
MD5: 659cf4c6baa87b082227540047538c2a
Size: 25169 bytes
Version: 1.3
Binary: True
Linearized: False
Encrypted: False
Updates: 0
Objects: 18
Streams: 5
Comments: 0
Errors: 2
Version 0:
Catalog: 27
Info: 11
Objects (18): [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 22, 23, 24, 25, 26, 27, 28]
Errors (1): [11]
Streams (5): [5, 7, 9, 10, 11]
Encoded (4): [5, 7, 9, 10]
Objects with JS code (1): [5]
Suspicious elements:
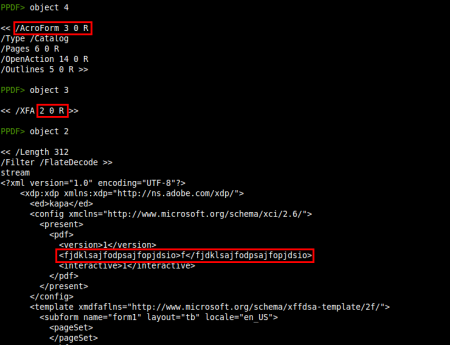
/AcroForm: [27]
/OpenAction: [1]
/JS: [4]
/JavaScript: [4]
getAnnots (CVE-2009-1492): [5]
Now we can see some statistics and information about the document. We can see some errors too, proof that it's not a normal PDF file: